Automating Detection of "Random-Looking" Algorithmic Domain Names

“… He shall separate them one from another, as the shepherd separateth the sheep from the goats…” Matthew 25:32 (Douay-Rheims Edition)
I. Introduction
We can split the domain names we see in passive DNS traffic according to many different taxonomies. For example, we can talk about:
- Domains in traditional ICANN “gTLDs” vs. domains in country-code “ccTLDs” vs. new gTLD domains
- Traditional LDH (Letter/Digit/Hyphen) ASCII-only domain names vs Internationalized Domain Names
- Recently-first-seen domains vs. long-established-and-heavily-used domains etc.
Today we’re going to talk about a different way to categorize domain names:
- Semantically-meaningful “regular” or “real” domain names: these are domain names that have been manually created by humans and which often refer to a location, a business, a product or service, a hobby or sport, a performer or band, or some other well-defined person/place/thing/concept, typically characterized by “recognizable words” as part of the domain. These names are often relatively short and easily remembered and typed into a browser. They’re typically purchased to be used for the foreseeable future, or at least for multiple years. We’re NOT interested in these sort of “regular” or “real” domain names today.
- Hashed DNSSEC-related pseudo-domain names: Nor are we interested in a second class of pseudo-domain names, the seemingly “random-looking” names associated with DNSSEC NSEC3/RRSIG records, which are actually hashed values associated with other names. For example:
$ dnsdbq -r 0vkcr4bccrjhivmsodse7h90d9ns9851.com/RRSIG -A1d -l 1
;; record times: 2019-03-16 05:19:46 .. 2019-03-20 05:20:42
;; count: 6593; bailiwick: com.0vkcr4bccrjhivmsodse7h90d9ns9851.com. RRSIG NSEC3 8 2 86400 1553318330 1552709330 16883 com. fCRQh2uMY29qtm75l5t3lTjnTLMxjP2ptz2OX6oZImHW+hkKmJvK4B+9 pSZHtudReziEUmkJnUKl6ZLLe07nSTXRxcNvkjM5rImW7eQH9rkpv2cd I0ajdLESUrkisB4zWrBJvDWXKyR1SGTtdftXcInPHn23Exd/flaR1WcK 6hk=
While that’s a “real” RRSIG record, you will not find a corresponding “A”/”AAAA”/”CNAME” record in passive DNS, nor anything in Whois. We’re not interested in hashed NSEC3/RRSIG names today, either.
- Long Random-Looking Algorithmic Domain Names: We ARE interested in a third class of domain names — these are “synthetic” domain names that are commonly generated via computer algorithms (rather than on a “onesie-twosie” basis by humans or as a result of DNSSEC-related operations).
These “algorithmic” or “synthetic” domain names are longer than normal domain name, “look random,” and are built with letters and numbers arranged in improbable combinations that would normally be “impossible” for humans to remember (and which would be very tedious to routinely “type-in-by-hand” into a web browser or other client).
Note that we’re NOT talking about fully-qualified domain names where the as-would-be-registered domain name looks “normal” EXCEPT for the presence of a weird “hostname” that’s been prepended to that name. We’re interested in cases where non-DNSSEC-related domain names — *the as-would-be-registered domain name itself* — looks “random.” These names may be registered in order to be used, or they may be registered “pre-emptively” in order to prevent someone else (such as a botmaster) from being able to register and use those names. That said, we’re not going to dive into the,”So why are algorithmic domain names being created in the first place?” question today; today our focus is just on FINDING those sort of domains in Farsight SIE Channel 204 traffic.
- Other Names: There are still some other names that don’t fit any of the three categories mentioned above; for now, we’ll just call this residual category, “Other.” An example of something that might end up in “Other” would be algorithmic domain names created by concatenating multiple English words together. Hypothetically:
scuba-snowshovel-saute-snapdraggon[dot]com.
II. Moving Beyond “We Know ‘Em When We See ‘Em”
When it comes to identifying algorithmic domain names, most analysts “know them when they see them.”
That’s great if you’re just scanning a short list of domains, but doesn’t scale well when confronting lists of hundreds of thousands or millions of candidate domain names. A detection algorithm is needed so the process can be automated. Random-looking domains will normally NOT include recognizable English words. Therefore, the core of one heuristic for spotting algorithmic domain names would be to look for domain names that contain zero embedded English words.
In using that rule-of-thumb, obviously we’ll be disregarding other conceivable types of algorithmically-constructed domain names (such as our
scuba-snowshovel-saute-snapdraggon[dot]com
domain). That sort of domain name, while algorithmic, would obviously fail to be detected by our “no English words in the domain name” heuristic. We could create an alternative heuristic that WOULD be able to recognize domain names created by concatenating English words together, but for now, we’re just going to focus on random-looking algorithmic domains that don’t contain English words, and ignore other algorithmic domain name construction algorithms.
We can refine our core heuristic further. For example:
- Algorithmic domain names are often longer than regular domain names. We could thus consider excluding names that are less than six or seven or eight characters long.
- Algorithmic domain names will often have unusually high Shannon entropy (perhaps 3.5+). To be very careful, we might exclude those with very low Shannon entropy.
- Algorithmic domain names may also often have an unusual distribution of letters and numbers and dashes, such as far-more-than-normal numbers or dashes.
We’ll explore some of these areas later in this article.
We also want to be sure to acknowledge up front that there has been significant formal academic work around algorithms for detecting domain generation algorithms (“DGAs”). It is not our intention to try to “compete” with that formal work, nor to tie the names we find to particular DGAs.
Rather, our goal today is just to demonstrate a pragmatic approach to finding algorithmic-looking domain names in “real-life traffic” as seen on Farsight Security SIE Channel 204.
III. English Word Lists
In order to identify embedded words, we’ll need a “vocabulary list” of English words. One source for English words is SCOWL, the Spell Checker Oriented Word Lists and Friends. We’ll use the web interface to actually create our list:
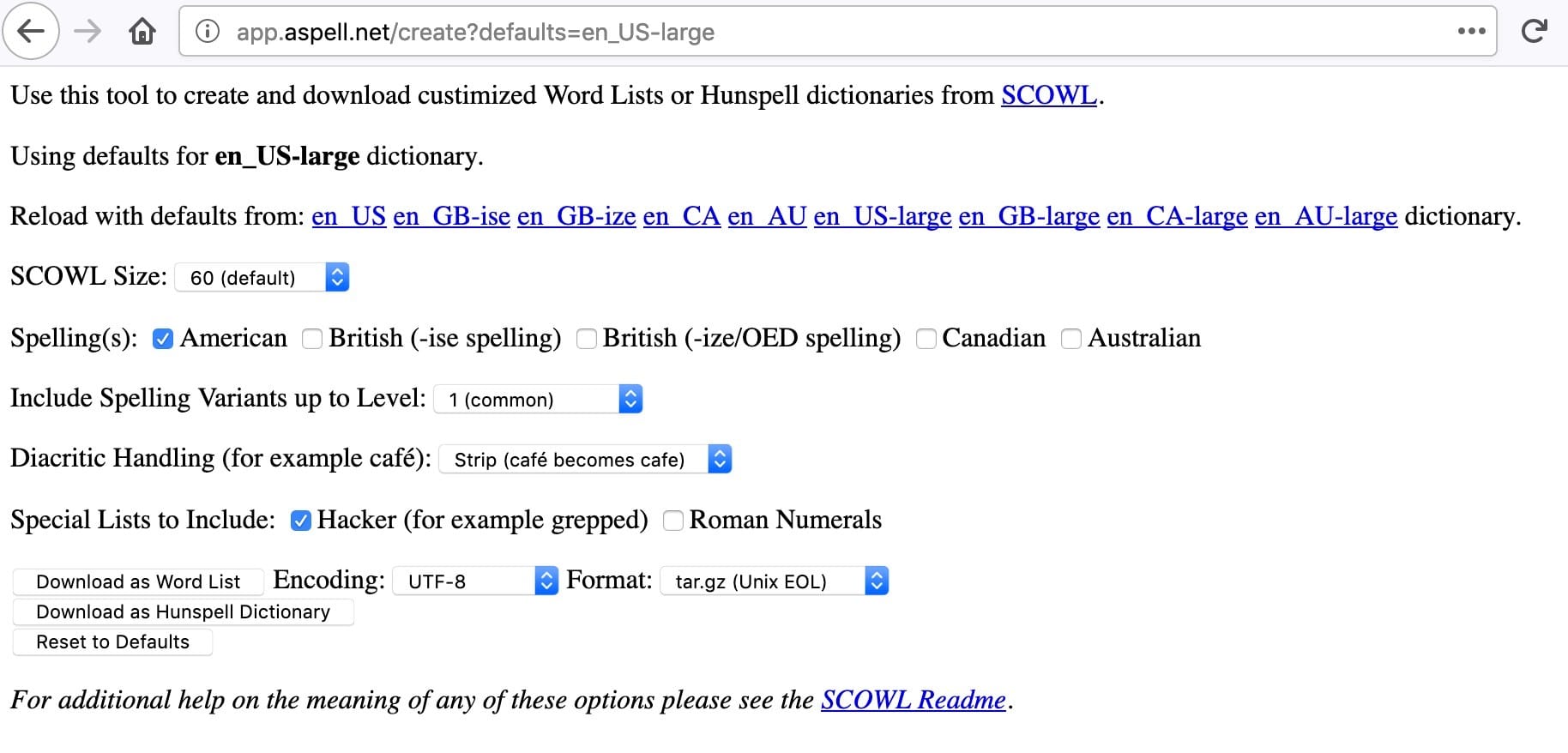
Figure 1. Settings For Our Downloaded List of Words
After downloading the list we’ve just created, we’ll untar it and check to see how many words it contains:
$ tar xfv SCOWL-wl.tar.gz
$ cd SCOWL-wl
$ wc -l words.txt
123601 words.txt
Reviewing the words in the
words.txt
file, we immediately noticed that it contained words with apostrophes and that some of the words (e.g., proper nouns) were mixed case. Since domains can’t contain words with apostrophes, we dropped all words with apostrophes. And because domain names are case insensitive, we also forced all the words to be lowercase only, thereby simplifying later comparisons. After sorting and uniquifying what remained, our list was reduced to roughly 88,000 words:
$ grep -v "'" words.txt > words2.txt <-- double quote, tick mark, double quote
$ tr '[:upper:]' '[:lower:]' < words2.txt | sort -u > words.txt
$ wc -l words.txt
87881 words.txt
For comparison, it has been reported that a typical 20-year-old American knows about 42,000 words, so we’d expect this list to encompass most commonly used English words (and then some). If that list is too inclusive (or not inclusive enough), you can obviously tweak the “SCOWL size” variable in the web form to get a larger or smaller list to suit your preferences. We might also want to supplement that list with a list of common Internet/computing/networking-related “jargon” terms, and a list of common abbreviations and acronyms.
IV. Code To Find Domain Names That DON’T Contain English Words
In addition to a list of English words, we also need a program to actually look for words in text. This article provides a nice conceptual starting point, although we’ll need to modify that algorithm for our unique requirements. To meet our specific needs, our Python program will need to:
- Read a sequence of domain names from <STDIN> for evaluation
- Carve off the domain names’s effective-top-level-domain per the Public Suffix List (PSL).
- Force the as-read domain name to be all lowercase
- Filter out any defined-to-be-out-of-scope domain names
- Check just the effective 2nd-level label (e.g., the effective 2nd-level domain name without the effective TLD) for recognizable words. We’ll only consider entries from the word list to be “words” if they’re at least three characters long (so “a”, “an”, “at”, “be”, “to” and so forth won’t “count”)
- Finally, we’ll output:* The number of recognizable 3-character-or-longer words found in the effective 2nd-level label* The length in characters of the 2nd-level domain name’s effective 2nd-level label part* The effective 2nd-level label* The effective TLD (“1st-level”) label* A list of the words found embedded in the effective second-level label (if any).
What domains might be “out of scope” and “subject to filtering?” Well, we’ll:
- Skip all “popular” domain names (to avoid false positives).
- Skip any effective top level domains without a second-level label (such as just tk or just co.uk)
- Skip any internationalized (“punycoded”) domain names (e.g., names that contain “xn- – “)
- Skip any
ip6.arpaor
in-addr.arpa
- domains
- Skip any domains names which have an all numeric second label (e.g.,
00112233445566778899[dot]tk)
For example after processing, the words found in the domain name
bellsouthyahoo[dot]com
were:
9, 14, bellsouthyahoo, com, bell, bells, ell, ells, out, sou, south, thy, yahoo
The
bellsouthyahoo[dot]com
name does NOT look like a “random” algorithmic domain even though it is 14 characters long because it has 9 identifiable words extracted from the 2nd-level label.
Contrast that with a name that DOES look random, in which NO identifiable words were found, such as:
0, 34, aa625d84f1587749c1ab011d6f269f7d64, com
You can see the code we came up with for this in Appendix I.
V. Guarding Against False Positives: Whitelisting “Popular” Domains
As much as we want to find algorithmic domain names that lack English words, we also want to carefully avoid any popular “real” domain names. Avoiding those will give us insurance against most potential “false positives”:
Figure 2. False Positives and False Negatives
Well-defined “popular” domains are ones that are on any of a number of “top N” lists such as the Alexa One Million Top Domains, the Majestic Top One Million domains, or the Domcop Top 10 Million domains.
The article, “Comparison Of Alexa, Majestic & Domcop Top Million Sites” does a nice job of laying out how to retrieve and extract domains from those lists.
To prepare a consolidated white list from those raw lists, we’ll:
- Simplify the domain names from those three lists to just their effective-top-level domains, and
- Combine and dedupe the lists with sort and uniq.
This combined list has 8,650,286 domains which we’ll define as “exempt” from being tagged as “random-looking” algorithmic domain names. Does this leave us open to potentially missing a true “random-looking” algorithmic domain name that’s somehow also “popular?” Yes. There are definitely some pretty “random-looking” domains in that combined list, but we believe the value of protecting against accidentally mis-including popular domains outways the risk of having “false positives.”
VI. Building A Test Corpus
Having developed code to find at least one class of algorithmic domains, we now need to test our code and “whitelist” on some real data (our “test corpus”).
To build a test corpus for initial assessment, we logged into a blade server at the Security Information Exchange (SIE) which has access to Channel 204. We then pulled ten million RRnames and RRtypes with the command:
$ time nmsgtool -C ch204 -c 10000000 -J - | jq --unbuffered -r '"\(.message.rrname) \(.message.rrtype)"' > ten-million-domains-to-test.txt
Because Channel 204 is a fairly busy channel, it only took a little over five minutes to pull that sample — the time command reported:
real 5m11.123s
user 6m4.932s
sys 0m29.812s
The output from our program consisted of a list of fully qualified domain names and associated record types:
$ more ten-million-domains-to-test.txt
phaodaihotel.com[dot]vn. A
cleancarpetandduct[dot]com. SOA
phaodaihotel.com[dot]vn. NS
cleancarpetandduct[dot]com. NS
imap.klodawaparafia[dot]org. CNAME
app[dot]link. AAAA
villamarisolpego[dot]com. NS
www.synapseresults.com.cdn.cloudflare.net. A
roadvantage[dot]com. SOA
plefbn59gl6bvbdp21haguljb51mbp7c[dot]nl. NSEC3
i6pangjmmi77sn4bt560edcnft2877a7[dot]by. NSEC3
i6pangjmmi77sn4bt560edcnft2877a7[dot]by. RRSIG
plefbn59gl6bvbdp21haguljb51mbp7c[dot]nl. RRSIG
gamamew-org[dot]cf. NS
egauger[dot]com. NS
[etc]
Note that some of the “random looking” domain names in that brief sample are actually hashed DNSSEC-related records (NSEC3 and RRSIG record types) as mentioned in Section I. We’ll exclude NSEC3 records and RRSIG records by saying:
$ grep -v " NSEC3" ten-million-domains-to-test.txt | grep -v " RRSIG" > ten-million-domains-to-test-without-dnssec.txt
$ wc -l ten-million-domains-to-test-without-dnssec.txt
8573184 ten-million-domains-to-test-without-dnssec.txt
For the curious, there were 435,709 NSEC3 records and 991,107 RRSIG records excluded by that filtering.
We’re also going to exclude internationalized domain names (“IDNs” have Punycoded names beginning with xn--). We’ll also drop names that end in \.arpa\. (this last filter is meant to catch any ip6.arpa. or in-addr.arpa. entries). We can also drop the record type data column, since we’ll no longer need it to filter NSEC3 or RRSIG records:
$ grep -v "xn--" ten-million-domains-to-test-without-dnssec.txt | grep -v "\.arpa\. " | awk '{print $1}' > ten-million-domains-to-test-without-dnssec-idn-or-arpas.txt
$ wc -l ten-million-domains-to-test-without-dnssec-idn-or-arpas.txt
8032040 ten-million-domains-to-test-without-dnssec-idn-or-arpas.txt
There were 41,101 internationalized domain names and 500,043 names that ended in \.arpa\.
We’ll then reduce the remaining domains to only their delegation points (for example, www.example.com –> example.com) with a popular little perl script called 2nd-level-dom-large that reads and processes those domains record-by-record (see Appendix II):
$ 2nd-level-dom-large < ten-million-domains-to-test-without-dnssec-idn-or-arpas.txt > ten-million-domains-to-test-2nd-level.txt
Having dumped the hostname part of the fully qualified domain names, we may now potentially have duplicate entries. We’ll deduplicate those domains by sorting and uniq’ing them:
$ sort ten-million-domains-to-test-2nd-level.txt > ten-million-domains-to-test-2nd-level-sorted.txt
$ uniq < ten-million-domains-to-test-2nd-level-sorted.txt >
sorted-and-uniqed-ten-million.txt
$ wc -l sorted-and-uniqed-ten-million.txt
3566037 sorted-and-uniqed-ten-million.txt
VII. Running Our Program To Find English Words in Our Test Corpus
We were then ready to test our find-a-word procedure. The Python code in Appendix I has been set to only test for English words that are equal to or greater than three characters in length. Some additional filtering is also done; see the
find-words.py
code. This takes our effective number of domains for analysis down to just 3,131,227 domains:
$ ./find-words.py < sorted-and-uniqed-ten-million.txt > ten-million-output.txt
$ gsort -t',' -k1n -k2nr < ten-million-output.txt > sorted-ten-million-output.txt
$ uniq sorted-ten-million-output.txt > sorted-and-uniqed-ten-million-output.txt
$ wc -l sorted-and-uniqed-ten-million-output.txt
3131227 sorted-and-uniqed-ten-million-output.txt
The distribution of 3,131,227 2nd-label lengths (measuring the lengths in characters of just the effective 2nd-labels) looks like:
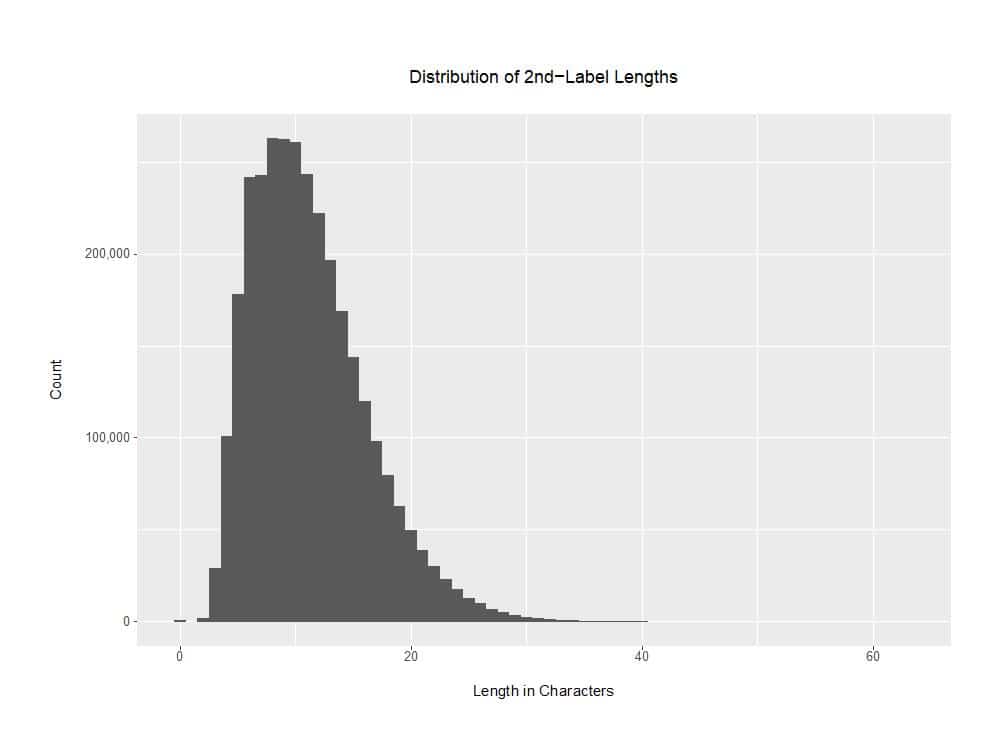
Figure 3. Distribution of 2nd-Label Lengths
A copy of the R program used to create that graph can be found in Appendix III.
The distribution of the number of words found per effective 2nd-label is a nice measure of the inclusivity of our word list. If our word list does a good job of capturing all the words that people use when creating domain names, we should see relatively few “zero words found” domain names except for truly random-looking junk. We’d also expect that a relatively large number of words would be able to be found embedded in at least some names.
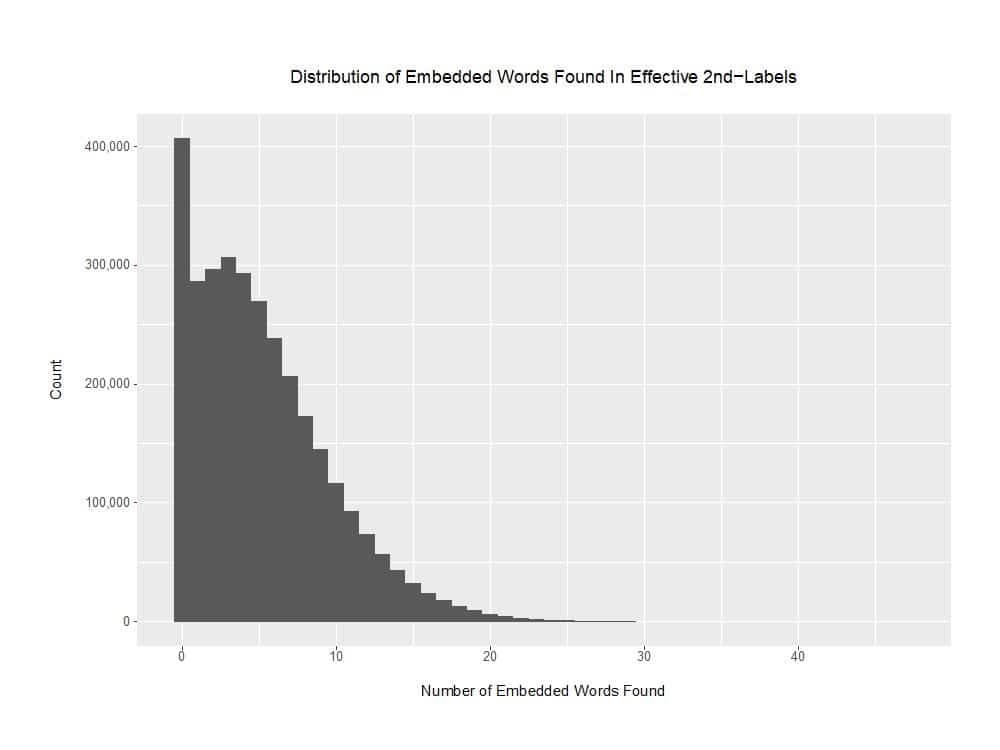
Figure 4. Number of Embedded Words Found in Effective 2nd-level labels
Here are some selected tabular “cut points” from the sorted 3,131,227-line output file from our “English words-only” run:
# of Words Starting Cumulative % Words In % of
Found On Line of Complete List This "Slice" Complete List
0 1 0% 406,841 12.99%
1 406,842 12.99% 286,664 9.16%
2 693,506 22.15% 297,230 9.49%
3 990,736 31.64% 307,051 9.81%
4 1,297,787 41.45% 293,268 9.37%
5 1,591,055 50.81% 270,360 8.63%
6 1,861,415 59.45% 238,653 7.62%
7 2,100,068 67.07% 206,452 6.59%
8 2,306,520 73.66% 173,525 5.54%
9 2,480,045 79.20% 145,115 4.63%
10 2,625,160 83.84% 384,083 12.26%
15 3,009,243 96.10% 98,280 3.13%
20 3,107,523 99.24% 19,508 0.62%
25 3,127,031 99.87% 3,522 0.11%
30 3,130,553 99.98% 656 0.02%
40 3,131,209 99.999% 18 0%
47 (max) 3,131,227 100.00%
The largest number of “embedded words” found was 47, for the vaguely-threatening-sounding second-label string howdoesdonaldtrumpsaythesethingsandnotgethospitalized:
`47, 53, howdoesdonaldtrumpsaythesethingsandnotgethospitalized, com, ali, and, doe, does, don, dona, donald, ese, ethos, get, gsa, hes, hing, hings, hos, hosp, hospital, hospitalize, hospitalized, how, ing, ital, liz, not, pit, pita, rum, rump, rumps, san, sand, say, set, seth, spit, tali, the, these, thin, thing, things, tho, trump, trumps, ump, umps, zed`
Digging into the 3,131,227 observations in
sorted-and-uniqed-ten-million-output.txt
, we can see that our code successfully identified many zero-embedded-English-words algorithmic-looking names, including:
0, 20, 3194df72cec99745647d, date
0, 20, 4cb619a293b854c7269a, date
0, 20, 58e20e431fd16ecea0cc, date
0, 20, 5cac157ee96e87a7bb59, date
0, 20, 605b4274b01e6840e84b, date
0, 20, 65a0163dddfbd7030f48, date
0, 20, 65v1d7rixqtu6ixg65hm, ws
0, 20, 6d69c6ff6eb7e8facf18, date
0, 20, 88f0289c6f7e1f0b3cf9, date
0, 20, 9111304db6c05e5473a8, date
0, 20, 99990002188338d9dc5e, date
0, 20, 9ee08f9b1e36e1a3f880, date
0, 20, ab032283869929420167, win
0, 20, ab032302933987702253, win
Interpreting the small set of observations just mentioned:
- The first two values on each line shown above are (a) the number of words found and (b) the length of the second-label. For this most recent block of examples, the number of embedded words found is always zero, and the length of the second-level label is always 20.
- The third and fourth values represent the actual second-label and the effective-top-level domain.
- Normally the fourth value would be followed by a list of embedded words found, but in this case obviously there were none.
We can use
to confirm that those domains really DO exist in DNSDB… For example, asking to see just a single “A” answer (RRset) for 3194df72cec99745647d[dot]date:
$ dnsdbq -r 3194df72cec99745647d[dot]date/A -l 1
;; record times: 2018-03-08 00:40:40 .. 2019-03-06 13:09:49
;; count: 425; bailiwick: 3194df72cec99745647d[dot]date.
3194df72cec99745647d[dot]date. A 104.28.6.141
3194df72cec99745647d[dot]date. A 104.28.7.141
That random-looking domain happens to be currently hosted on/through Cloudflare.
VIII. Areas Where Some Potential Issues Were Noted
a) “Raw” TLDs: DNSDB data can include names with just one label (e.g., a TLD), or with two labels (a normal delegation point), and names with three or more labels (typically “fully-qualified domain names”).
We saw 850 raw effective-top-level domains. These can readily be identified by noting the “0, 0, ,” start to each of the relevant lines (e.g., the second-level part was of missing/of “zero length”, and obviously we won’t find any embedded words in a zero-length second-level label).
[...]
0, 0, , asia
0, 0, , asn.au
0, 0, , associates
0, 0, , at
0, 0, , attorney
0, 0, , auction
0, 0, , audio
0, 0, , auto
0, 0, , avianca
0, 0, , aw
0, 0, , ax
0, 0, , az
0, 0, , azure
[etc]
b) Domains With Extremely LOW Shannon Entropy Values:
While most of the “zero words found” domains truly did look random, there were some “zero-words-found” domains that nonetheless had readily-discernible-to-a-human-analyst NON-random patterns, such as runs of a single characters. These labels would have low levels of Shannon Entropy. To get a handle on this, we modified our Python code to compute and prepend the Shannon Entropy value associated with the “second-label” to each line (see Appendix IV). For example:
[Shannon Entropy, Words Found, second-level label length, 2nd-level label, TLD]
0, 0, 7, jjjjjjj, cn
0.6500224216483541, 0, 6, 55555f, com
0.8112781244591328, 0, 8, z666z666,com
0.9709505944546686, 0, 5, ggvvg, cn
Shannon entropy values less than one are quite uncommon for domain second-level labels, at least based on our sample:
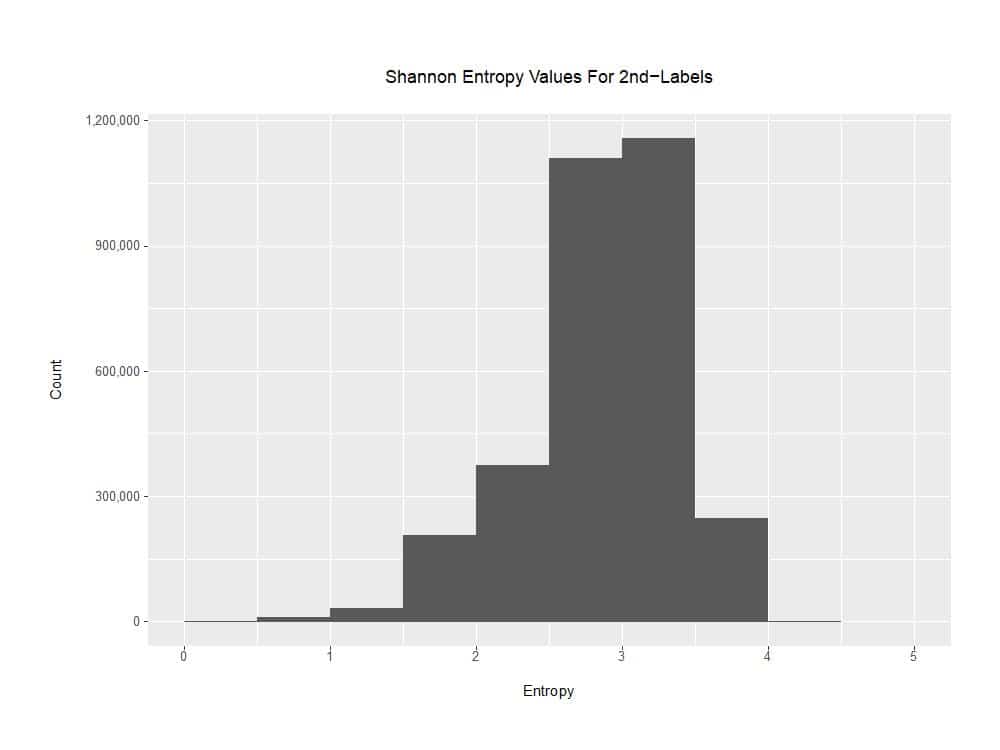
Figure 5. Shannon Entropy Distribution for the 2nd-Label of the Test Corpus
c) Domains with “Dashed” Names:
We also noticed some domains with large numbers of dashes, such as:
2.766173466363126, 0, 62, 1-2-3-4-5-6-7-8-9-10-11-12-13-14-15-16-17-18-19-20-21-22-23-24, com
1.191501106916491, 0, 54, 0-0-0-0-0-0-0-0-0-0-0-0-0-33-0-0-0-0-0-0-0-0-0-0-0-0-0, info
1.228538143953528, 0, 54, 0-0-0-0-0-0-0-0-0-0-0-0-0-53-0-0-0-0-0-0-0-0-0-0-0-0-0, info
2.6081816167087406, 0, 23, h-e-r-n-a-n-c-o-r-t-e-s, com
2.695138138447871, 0, 23, f-i-v-e-d-i-a-m-o-n-d-s, com
2.5358577759182794, 0, 19, t-i-p-o-g-r-a-f-i-a, ru
2.641120933813016, 0, 19, m-y-w-e-b-p-o-k-e-r, eu
2.395998870534841, 0, 17, p-o-r-t-f-o-l-i-o, ru
2.5580510765444573, 0, 17, b-o-o-m-e-r-a-n-g, com
2.5580510765444573, 0, 17, p-r-e-j-u-d-i-c-e, com
1.9237949406953985, 0, 16, i--n--s--u--r--e, com
2.4956029237290123, 0, 14, ip-167-114-114, net
2.495602923729013, 0, 14, ip-144-217-111, net
2.495602923729013, 0, 14, ip-167-114-116, net
2.556656707462823, 0, 14, ip-144-217-114, net
2.610577243331642, 0, 14, ip-217-182-228, eu
2.6384600665861555, 0, 14, ip-167-114-119, net
2.6384600665861564, 0, 14, ip-149-202-222, eu
These patterns obviously suggest that there might be filtering value to heuristics that tally the number of dashes in a domain name, or to stripping dashes as a preliminary pre-processing step.
Checking the data, and exempting names exhibiting a “potentially-normal” number of dashes (e.g., zero through three dashes) from analysis, we see a distribution for the remaining names that looks like:
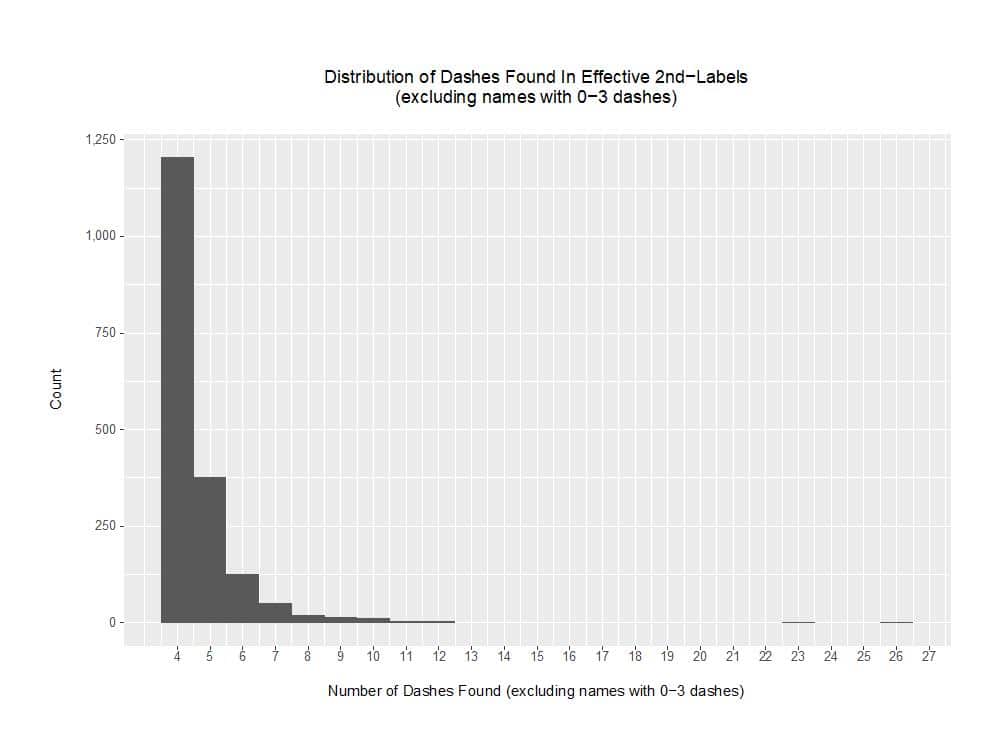
Figure 6. Distribution of Dashes Found in Effective Second-Labels (excluding names with 0-3 dashes)
Given the existence of domains with this sort of atypical dash usage, one could envision a pre-processing rule that strips all dashes prior to searching the transformed name for words, although we’re not doing so at this time.
d) Non-English Words:
In other cases, inspection of the output makes it clear that if we’d included dictionaries for languages other than English, we would have detected foreign-language words. For example:
0, 23, trikolor-tv-elektrougli, ru
0, 20, muehlheim-aerztehaus, de
0, 16, ce-vogfr-aulnoye, fr
0, 15, buetler-elektro, ch
0, 15, cipriettigiulia, it
Obviously our initial focus on only English words was perhaps inappropriately provincial. The Internet is international, and has users who rely on French, German, Italian, Portuguese, Russian, Spanish, and every other language you can imagine.
What lists of foreign words can we find? First, note that we only want Romanized/Latin word lists (no Arabic script word lists, no Chinese/Japanese/Hangul script word lists, no Cyrillic word lists, etc.)
One potentially-rich source of Romanized foreign language words is the lists of foreign language words compiled for auditing password practices with password cracking software. See, for example, the 20+ foreign language word lists here We’ll assume that you’ve downloaded and merged those word lists, removing any words that include characters other than letters/digits/hyphens from the combined list.
After adding the new word lists and rerunning our find-words.py script with our new combined English-plus-foreign word list, we find far more embedded words, as reflected in FEWER domains with just a small number of words found.
For example, as shown in the following table, when we had only English words to look for in domain names, there were 406,841 domains where we found no words. Changing the word list to be a combination of English AND foreign language words, and suddenly we’re down to only 94,011 “domains with no embedded words,” aka random-looking algorithmic names.
Words ENGLISH WORDS ONLY COMBINED LANGUAGE LIST
Found Starting On % of Lines Starting On % of Lines DIFFERENCE
0 1 0% 1 0%
1 406,842 12.99% 94,012 3.00% 9.99%
2 693,506 22.15% 213,816 6.83% 15.32%
3 990,736 31.64% 329,519 10.52% 21.12%
4 1,297,787 41.45% 455,640 14.55% 26.90%
5 1,591,055 50.81% 566,168 18.08% 32.73%
6 1,861,415 59.45% 677,469 21.64% 37.81%
7 2,100,068 67.07% 807,436 25.79% 41.28%
8 2,306,520 73.66% 929,783 29.69% 43.97%
9 2,480,045 79.20% 1,062,576 33.93% 45.27%
10 2,625,160 83.84% 1,196,525 38.21% 45.63%
15 3,009,243 96.10% 1,822,685 58.21% 37.89%
20 3,107,523 99.24% 2,311,625 73.82% 25.42%
25 3,127,031 99.87% 2,648,053 84.57% 15.30%
30 3,130,553 99.98% 2,862,546 91.42% 8.56%
40 3,131,209 99.999% 3,060,974 97.76% 2.24%
47 3,131,227 100.00% 3,106,213 99.20% 0.80%
50 3,115,421 99.50% 0.50%
60 3,127,871 99.89% 0.11%
70 3,130,530 99.98% 0.02%
80 3,131,044 99.99% 0.01%
90 3,131,185 99.999% 0.001%
100 3,131,213 99.999% 0.001%
116 (max) 3,131,227 100% 0%
This is a significant improvement over the English-only word list. See the green-shaded region in the following graph:
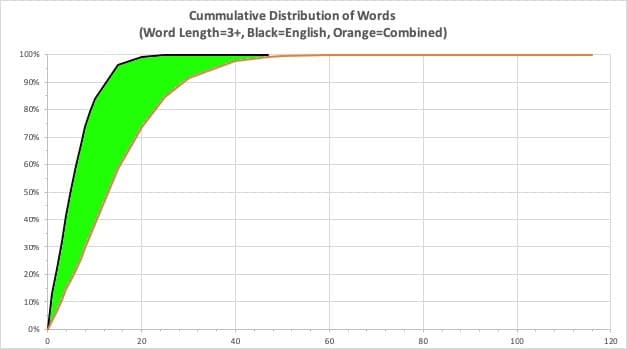
Figure 7. Improvement in Word Discernment, English-Only to Combined Language Word List
For the curious, the domain name containing the largest number of English-OR-foreign-language words was:
116, 59, escuelaprimariaurbanacrescenciocarrilloyanconaturnomatutino, com, acr, acre, acres, ana, anac, anc, anco, ancon, ancona, apr, apri, aprimar, ari, aria, arr, arri, atu, atut, aur, ban, bana, banac, car, carr, carri, carril, carrillo, cen, cenci, cencio, cio, con, cona, conatu, cre, cresce, cue, ela, enc, esc, esce, escuela, iau, iaur, ill, illo, ima, imar, imari, ino, ioc, ioca, lap, llo, loy, mar, mari, maria, mat, matu, matuti, matutino, nac, nacre, nacres, nat, natu, natur, nci, nco, nom, noma, oca, oma, omat, ona, onatu, oya, pri, prim, prima, primar, primari, primaria, rba, res, ria, riau, ril, rill, rim, rima, rimar, rimari, rno, rri, sce, scen, scu, tin, tino, tur, turn, turno, tut, tuti, tutin, uel, urb, urba, urban, urbana, urn, uti, utino, yan
IX. So What Do Our Final “Goat” Domains Look Like?
The final code that you see in Appendix IV considers only effective second-level domains, and filters out:
• RRSIG and NSEC3 pseudo domains
• Domains found in the consolidated whitelist
• IDN domains (“xn--“)
• ip6.arpa and in-addr.arpa domains
• Domains of the form ip-–-*
• Names with four or more dashes
• Domains with all numeric 2nd-labels
• Domains with one or more embedded English or foreign-language words
• Domains with 2nd-labels that have Shannon entropy <= 1
• Domains with 2nd-level labels 7 characters or less in length
Looking at what’s left (sorted in descending order by Shannon entropy) we see 5337 domains that look like:
We could now look for commonalities among those domains such as shared hosting IPs, common nameservers, registration via the same registrars, etc. In part two of this series, we’ll dig in on the domains we’ve found.
X. Conclusion
You’ve now seen how a naive model, crude as it may be, can still help us to find algorithmic domain names. Can we do better? We’ve hinted at some things we can try, but you’ll have to wait for the next part of this series to see exactly where else this analysis will take us.
In the mean time, why don’t you talk with a Farsight Sales Executive about access to Channel 204 at the Security Information Exchange? With access to Channel 204, you could see how your own ideas for spotting algorithmic domain names measure up!
The Farsight Security Sales Team can be reached at [email protected]
Appendix I. find-words.py (in Python 2)
#!/usr/local/bin/python2
import string
import sys
import re
import tldextract
## read in the dictionary
## we will compare words found in stdin against words in this "dictionary"
dictionary = set(open('words.txt','r').read().split())
max_len = max(map(len, dictionary))
## read in the combined list of popular domains we want to avoid
protected = set(open('combined-millions-unique.txt','r').read().split())
max_len_p = max(map(len, protected))
## ensure the TLD extractor knows to obey the Public Suffix List
extract = tldextract.TLDExtract(include_psl_private_domains=True)
extract.update()
## read in candidate domain names for processing
for line in sys.stdin:
## create an initial empty set
mydomainnames = set()
justfound = line.lower().rstrip()
is_not_whitelisted = not(justfound in protected)
is_not_an_idn_name = (justfound.find("xn--") == -1)
is_not_an_ip6_arpa_name = (justfound.find("xn--") == -1))
is_not_an_in_addr_arpa_name = (justfound.find("in-addr.arpa") == -1)
if (is_not_whitelisted and
is_not_an_idn_name and
is_not_an_ip6_arpa_name and
is not_an_in_addr_arpa_name):
extracted = tldextract.extract(justfound)
justfound = extracted.domain.replace(" ","")
if (justfound.isdigit() == False):
justfound_length = len(justfound)
if (justfound_length >= 8):
efftld = extracted.suffix
words_found = set() #set of words found, starts empty
for i in xrange(len(justfound)):
chunk = justfound[i:i+max_len+1]
for j in xrange(1,len(chunk)+1):
word = chunk[:j] #subchunk
if word in dictionary:
if len(word) > 2: words_found.add(word)
words_found = sorted(words_found)
number_of_words = len(words_found)
print str(number_of_words)+", "+str(justfound_length)+",",
if number_of_words > 0:
print justfound+", "+efftld+",",
else:
print justfound+", "+efftld
if number_of_words > 0:
print str(words_found).replace("[","").replace("]","").replace("'","")
Appendix II: 2nd-level-dom-large
#!/usr/bin/perl
use strict;
use warnings;
use IO::Socket::SSL::PublicSuffix;
my $pslfile = '/usr/local/share/public_suffix_list.dat';
my $ps = IO::Socket::SSL::PublicSuffix->from_file($pslfile);
while (my $line = <STDIN>) {
chomp($line);
my $root_domain = $ps->public_suffix($line,1);
printf( "%s\n", $root_domain );
}
Appendix III. Small R Script To Produce Distribution of Word Lengths
#!/usr/local/bin/Rscript
mydata <- read.table(file="word-length-counts.txt",header=T)
pdf("word-length-distribution.pdf", width = 10, height = 7.5)
library("ggplot2")
library("scales")
mytitle <- paste("\nDistribution of 2nd-Label Lengths\n", sep = "")
theme_update(plot.title = element_text(hjust = 0.5))
p <- ggplot(mydata, aes(length)) +
geom_histogram(breaks=seq(-0.5, 63.5, by = 1)) +
labs(title=mytitle, x="\nLength in Characters", y="Count\n") +
scale_y_continuous(labels = function(x) format(x, big.mark = ",",
scientific = FALSE)) +
theme(plot.margin=unit(c(0.5,0.5,0.5,0.5),"in"))
print(p)
Appendix IV. find-words.py with combined language word list and Shannon Entropy Code (in Python 3)
#!/usr/local/bin/python3
import string
import sys
import re
import tldextract
import math
def entropy(s):
string_length = len(s)
lc = {letter: s.count(letter) for letter in set(s)}
temp=0.0
for i in lc:
temp=temp+((lc[i]/string_length) * math.log2(lc[i]/string_length))
if temp == 0.0:
return 0
else:
return -temp
## read in the dictionary
## we will compare words found in stdin against words in the dictionary
dictionary = set(open('combined-word-list.txt','r').read().split())
max_len = max(map(len, dictionary))
## read in the combined list of popular domains we want to avoid
protected = set(open('combined-millions-unique.txt','r').read().split())
max_len_p = max(map(len, protected))
## ensure the TLD extractor knows to obey the Public Suffix List
extract = tldextract.TLDExtract(include_psl_private_domains=True)
extract.update()
## read in candidate domain names for processing
mydomainnames = set()
for line in sys.stdin:
## ensure name is lowercase and is whitespace free
justfound = line.lower().rstrip()
## only process stuff NOT found in the whitelist
if not(justfound in protected):
## ANY of the following hit? Don't process it
## note that at this point the TLD is still there
## Start by checking for punycoded domains
if ((justfound.find("xn--") == -1) and
## and .arpa domains
(justfound.find("ip6.arpa") == -1) and
(justfound.find("in-addr.arpa") == -1) and
## and anything like ip-12-34-56
(not(re.search("ip-*-*-*",justfound))) and
## any names with 4 or more dashes
(justfound.count('-') <= 3)):
## now pull just the 2nd-label
extracted = tldextract.extract(justfound)
justfound = extracted.domain.replace(" ","")
## only keep 2nd-labels that have at least one non-numeric
if justfound.isdigit() == False:
## how long is the 2nd-label?
justfound_length = len(justfound)
## what's the 2nd-label's shannon entropy?
shan_ent = entropy(justfound)
efftld = extracted.suffix
words_found = set() #set of words found, starts empty
for i in range(len(justfound)):
chunk = justfound[i:i+max_len+1]
for j in range(1,len(chunk)+1):
word = chunk[:j] #subchunk
if word in dictionary:
if len(word) > 2: words_found.add(word)
words_found = sorted(words_found)
number_of_words = len(words_found)
## these should be our highly random names
if ((number_of_words == 0) and (shan_ent > 1) and
(justfound_length >= 8)):
rounded_shan=round(shan_ent,3)
print(rounded_shan, justfound, efftld)
Joe St Sauver Ph.D. is a Distinguished Scientist with Farsight Security®, Inc.
Read the next part in this series: ‘A Second Approach To Automating Detection of “Random-Looking” Domain Names: Neural Networks/Deep Learning’
Read more from DomainTools


