A Second Approach To Automating Detection of "Random-Looking" Domain Names: Neural Networks/Deep Learning


“Why this name, Keras? Keras (κέρας) means horn in Greek. It is a reference to a literary image from ancient Greek and Latin literature, first found in the Odyssey, where dream spirits (Oneiroi, singular Oneiros) are divided between those who deceive men with false visions, who arrive to Earth through a gate of ivory, and those who announce a future that will come to pass, who arrive through a gate of horn.” https://keras.io/#why-this-name-keras
“Keras (Indonesian): Hard” https://translate.google.com/
Section 1. Introduction
In part one of this series, Automating Detection of “Random-Looking” Algorithmic Domain Names, we described a method that we could use to find particularly-“random-looking” domain names present in SIE Channel 204 DNS traffic. That approach looked for domains that contained no English or foreign language words, and found 5,337 unique random-looking domains out of a five minute long/ten million record sample of SIE Channel 204 data. (We undoubtedly missed other names that were also truly random.)
Now, in part two of the series, we wanted to see if we could use neural networks/deep learning as an alternative way to uncover random-looking domains from that same traffic, training the neural network based on names we’d already found in part one.
We embarked on this work with some trepidation:
• Neural networks are at their best when detecting patterns, but we’re interested in identifying “random-looking” domain names, names that are basically “pattern-free.” Would this even work? We took solace from the “universality theorem,”[^1] but worried that our own limited neural network/deep learning skills MIGHT not be equal to the subtleties of this problem (then again, leveraging Cunningham’s Law,[^2] maybe one of you reading this can come up with a more elegant solution).
• As someone who formerly supported statistical users, I’ve always thought that theoretical considerations were key to developing a sound model. For example, in the “good old days,” you wouldn’t just run a stepwise regression and see what ad hoc “discovered” variables seemed to result in a model that appeared to deliver a “good fit”[^3] for one dataset.
• We know that neural networks/deep learning have achieved astronomical levels of hype,[^4] much like a handful of other technologies (such as blockchain[^5]). This article is, or is meant to be, “hype free,” and attempts to focus strictly on what we tried and what we found. Our primary goal is to show another approach to categorizing domains, and, perhaps, to also illustrate how complex neural networks/deep learning still can be, even when using “user-friendly” software tools.
• We also want to acknowledge up front the reality that truly understanding and explaining neural networks/deep learning requires advanced mathematics. Unfortunately, this blog is not really the right place for complex mathematical content. We’ve done our best to finesse that issue in the text below, sharing “rules of thumb” and “best practices” but omitting the math underlying and justifying those choices. We have provided references for most if not all of the rubrics used so that those who are prepared for more detail can dig in.
• While GPUs have come way down in price[^6] and can greatly accelerate the matrix operations underpinning machine learning, we’re just going to use a laptop for training our model. This limits our ability to employ some of the more sophisticated approaches simply because we don’t have weeks or months to devote to building and training a model for a blog article. Then again, we believe working with basic facilities helps to “keep this all real.”
Section 3. Installing The Software We’re Using
There are many ways to install the required Python-based software.[^15] We already had Python 3 installed, and since we like to have fine-grained control over what we install (and we prefer platform-independent native methods), we used pip3 to install the other packages we needed:^16
# pip3 install numpy
# pip3 install pandas
# pip3 install theano
# pip3 install keras
Because functionality may fundamentally vary with the version of the packages used, we note for the record the versions of the products we installed:
$ python3 --version
Python 3.7.3
$ python3 -c 'import numpy; print(numpy.__version__)'
1.16.4
$ python3 -c 'import pandas; print(pandas.__version__)'
0.24.2
$ python3 -c 'import theano; print(theano.__version__)'
1.0.4
$ python3 -c 'import keras; print(keras.__version__)'
Using Theano backend.
2.2.4
Later versions of those packages will also typically be fine (we don’t mean to ever discourage you from updating!)
FWIW, if you decide that you would rather use TensorFlow instead of Theano for your Keras backend, you can change that fundamental default in your .keras/keras.json preferences file.
My .keras/kersas.json file looks like:
{
"floatx": "float32",
"epsilon": 1e-07,
"backend": "theano",
"image_data_format": "channels_last"
}
Section 4. Pre-Processing A Domain Name Training Dataset, Based On Data From Part I of This Blog Series
In order to be able to run any machine learning analysis, you need data, ideally LOTS of data. Fortunately, we have boodles of domain names from the Farsight Security Information Exchange. [see https://www.farsightsecurity.com/solutions/security-information-exchange/ ]
We also have a strategy for distinguishing random-looking domains from normal domains, as outlined in part one of this blog series — this means that we have what we’ll need to train a new neural network/deep learning model on “pre-categorized” data.
It is critical that we correctly pre-process and then properly represent the underlying domain data. In particular, note that neural networks cannot directly ingest and process raw files of alphanumeric domain names — those names MUST be numerically coded. But how? Our pre-processing will take the domain name through a series of stages:
• Stage 1 – Original Data: Domain names will initially begin as a lowercase string (such as sample.com)
• Stage 2 – Vector of Individual Characters: We’ll then break that string apart into a vector of individual characters. For example, the 10 character string sample.com would get transformed into a vector of ten individual letters, ["s", "a", "m", "p", "l", "e", ".", "c", "o", "m"].
• Stage 3 – Index Of Each Character: We can then get the index (position/location) for each character from a defined list of characters such as 'abcdefghijklmnopqrstuvwxyz01234567890-_.'
We could also simply have taken the ordinal value of the characters from the ASCII character set, but that means starting with lowercase “a”=97 (decimal). We prefer having smaller numeric indicies, such as “a”=1, “b”=2, etc.
We can write a small Python3 code to demonstrate what we mean by this approach:
$ cat char-to-ord.py
#!/usr/local/bin/python3
string = "sample.com"
print ("Original string = ", string)
charvec = list(string)
print ("Vector of characters = ", charvec)
print ("Vector of coded values =", end =" ")
d = []
i = 0
while (i < len(string)):
temp = ord(charvec[i])
d.append(temp)
i = i + 1
print (d)
charset = "abcdefghijklmnopqrstuvwxyz0123456789-_."
dprime = []
i = 0
while (i < len(string)):
temp = charset.find(charvec[i])+1
if (temp != 0):
dprime.append(temp)
else:
dprime.append(0)
i = i + 1
$ python3 char-to-ord.py
Original string = sample.com
Vector of characters = ['s', 'a', 'm', 'p', 'l', 'e', '.', 'c', 'o', 'm']
Vector of coded values = [19, 1, 13, 16, 12, 5, 39, 3, 15, 13]
You can imagine encoding each of our normal or random-looking domains using this create-a-vector-of-codes approach, and in fact that’s what we’ve done, albeit with a small GNU Fortran program we call convert5.f (see Appendix I)
Our starting dataset is a file called combined.csv that contains both regular domain names and random-looking domain names from the first part of this blog series. Some of the domain names in that file are quite long, while others are rather short. Because neural networks/deep learning works best with uniform length training data, we are faced with the need to:
- Pad the short names to the length of the longest name,
- Truncate (chop) the too-long names to some common length we select, or
- Discard the too-long names entirely.
We decided to exclude any domains that are more than 20 characters long, and pad any names shorter than that length out to 20 characters.
Discarding domains greater than 20 characters in length is not as daring as it may seem since most names are actually twenty characters or less as shown in Figure 3 from part one of this series:
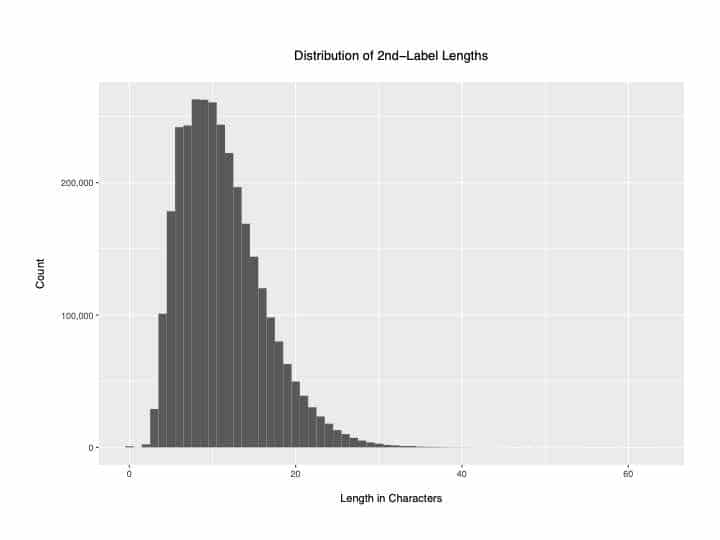
Figure 1. Distribution of domain lengths (from Part 1 of this blog series, figure 3)
We’ll do this “pruning” and “padding” with a little Perl^17 script called
trim-too-long
, as shown in Appendix II. In this specific case, we’ll say:
$ trim-too-long 22 < combined.csv > combined-20-or-less.dat
The alert reader will note that we’re actually triming to 22 characters, rather than 20 characters. That’s because the first two spaces on each line are actually taken up with the class into which that domain was placed (either 1 for random-looking, or 0 for normal)), followed by a comma separator. That’s then immediately followed by the domain names in string form. The breakdown of random-looking vs normal domains for the 20 character or less data looks like:
Table 1. Summary Class Statistics for Domains Length <= 20 (Training Data From Blog Part I)
That’s a dramatically asymetric class distribution: 99.83% of our cases are regular domains, and just 0.169% are random-looking domains. Given that imbalance, imagine a classification rule that says, “Just assume all observations are regular domains.” That simplistic rule would be “right” 99.83% of the time, even if that misses the whole point of this exercise![^18]
We can attempt to overcome this “prejudice” by weighting the data, as described in “How to set class weights for imbalanced classes in Keras?”^19 However, ultimately, we decided that we needed to oversample additional random-looking domain names, collecting supplemental random-looking domains for model-training purposes. We went back to SIE Channel 204 and pulled/processed an addition 1.5 billion records:
$ nmsgtool -C ch204 -c 1500000000 -J - | jq --unbuffered -r '"\(.message.rrname) \(.message.rrtype)"' > one.txt
[Exclude RRSIG, NSEC3, IDN and .arpa domains]
$ cat one.txt | grep -v " NSEC3" | grep -v " RRSIG" | grep -v "xn--" | grep -v "\.arpa\. " | awk '{print $1}' > two.txt
$ wc -l two.txt
1,168,890,556 two.txt [commas added for readability]
[reduce the domains to effective 2nd-level domains only]
$ 2nd-level-dom-large < two.txt > three.txt
[sort and uniquify the effective 2nd-level domains]
$ sort -T. three.txt > four.txt
$ uniq < four.txt > five.txt
$ wc -l five.txt
98,853,330 five.txt [commas added for readability]
[exclude names that contain an English or foreign language word >= 3 characters]
$ find-words.py < five.txt > six.txt
$ wc -l six.txt
226,185 six.txt [commas added for readability]
[merge random-looking domains with the old combined data, eliminating any duplicates]
$ cat combined-20-or-less.dat seven.txt | sort -u > new-combined-20-or-less-sorted.txt
$ wc -l new-combined-20-or-less-sorted.txt
3,264,272 new-combined-20-or-less-sorted.txt [commas added for readability]
$ awk '{print $1}' < new-combined-20-or-less-sorted.txt | sort | uniq -c
3,036,657 0 [commas added for readability]
227,615 1
Oversampling class 1 (the random-looking domains) substantially improved the distribution of our training data:
Table 2. Summary Class Statistics for The Upsampled Class=1 Domain Data, Length <= 20
We’re now ready to process our augmented domains with
convert5.f
(see Appendix I)
Assuming you have
GNU Fortran
^20 installed, compile and run that code by saying:
$ gfortran -o convert5 convert5.f
$ ./convert5 > new-tokenized-20-char.txt
After the code finishes running, we compress the output file with
gzip
^21 since Pandas and friends can automatically cope with compressed data files:
$ gzip -9 new-tokenized-20-char.txt
Uncompressed,
new-tokenized-20-char.txt
runs about 158MB; compressed, that data runs just 20 MB or so.
Section 5. Dealing With The Fact That Domain Names Are Inherently Categorical Data
There’s one more issue we need to address: the numerically-encoded characters from Section 4 are categorical measurements, and are not interval/ratio nor ordinal data.^22 Numerically-encoded character code values aren’t things we normally measure the way we do length, mass, velocity, temperature, crop yields in bushels-per-acre, contamination levels in parts-per-million, etc. This means that we can’t meaningfully perform mathematical operations on that data — we can’t add “r” to “s” and divide by “q” (even if numerically-encoded character values may make it appear as if that should be possible). We can’t even meaningfully “order” or “rank” numerically-encoded character values (except by superficially applying an agreed-upon mechnical collating sequence).^23 This means that we also can’t even apply non-parametric methods to that data.^24
We’re left with an ugly reality: the characters making up domain names are categorical (or “nominal”) data, and must be treated as such. When coding categorical data for an observation, something either “is” (or “has”) a particular categorical attribute, or it doesn’t. This status is normally represented using “dummy” or “indicator” variables (the machine learning community often prefers to refer to these as “one hot” variables).^25 Those variables are set to 1 if the attribute is present and 0 if the attribute isn’t present. Given a set of ten potential classes for a categorical variable, one class will normally be taken as the “default” class and the impact of the other nine attributes will be represented by a set of nine dummy variables.
Let’s now try to apply this approach to our domain names. If we assume each character in a domain name can be:
- One of the 26 lowercase letter from a to z
- One of the 10 digits from 0 to 9, or
- A dash, underbar character or dot
that implies 26+10+3=39 potential values for each character in a domain name, assuming an ASCII space (as used for padding) is our “base” category.
As previously mentioned, the number of characters in a domain name will vary, but we need a consistent length for our observations. Recall that figure 1, above, showed us that most of our names were 20 characters or less in length.
Therefore, we’re adopting a maximum domain name length of 20 by default for our encoded domain name representation, and trimming our dataset to only include domains of that length (or less) using the little piece of perl code that you can see in Appendix II.
So given all of the above, think of each dummy-coded domain name as consisting of 20 lines of data, one line for each character in the name.
1 2 3
1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9
a b c d e f g h i j k l m n o p q r s t u v w x y z 0 1 2 3 4 5 6 7 8 9 - _ .
1 s 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
2 a 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
3 m 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
4 p 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
5 l 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
6 e 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
7 . 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1
8 c 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
9 o 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
10 m 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
[followed by 10 rows of "all zeros" to get to 20 rows for the name]
Figure 2. Dummy Coding “sample.com”
A few final “fixups” we still needed to make to that:
• Rather than having 20 separate lines of 39 indicator variables, we’ll just string the whole set of 20 lines of 39 characters together, one after another, for each domain name. This means that each line will have 20*39=780 values per line.
• We’ll preface each of the lines with the actual class assignment we made during part one of this series, either 1 (random-looking) or 0 (normal), as shown in the original data file.
Obviously, attempting to dummy code our domains as categorical data this way is pretty inefficient and quickly becomes unwieldy/impracticable.
The “Keras way” around this problem is through the use of “embeddings,” which essentially map categorical variables into a multidimensional space. Some excellent introductions to the topic of embeddings include:
• Rutger Ruizendaal’s “Deep Learning #4: Why You Need to Start Using Embedding Layers,” see https://towardsdatascience.com/deep-learning-4-embedding-layers-f9a02d55ac12
• Will Koehrsen’s “Neural Network Embeddings Explained: How deep learning can represent War and Peace as a vector,” seehttps://towardsdatascience.com/neural-network-embeddings-explained-4d028e6f0526 and
• Cristopher Olah’s “Deep Learning, NLP, and Representations,” see http://colah.github.io/posts/2014-07-NLP-RNNs-Representations/
We’ll illustrate the use of embedding layers as part of formulating our model, below.
Section 6. Reading In Our Data and Extracting the X’s and Y
First, however, let’s read in our coded data.
All neural network/deep learning programs lean heavily on third party libraries. Our first job is to bring in the ones we’ll be using with import statements. We’ve prefaced each import with a comment explaining where that library/routine is explained or illustrated:
# http://www.numpy.org/
import numpy as np
# https://pandas.pydata.org/
import pandas as pd
# https://docs.python.org/3/library/sys.html
import sys
# https://stackoverflow.com/questions/7370801/measure-time-elapsed-in-python
from timeit import default_timer as timer
# https://keras.io/losses/
# https://keras.io/optimizers/
from keras import losses, optimizers
# https://keras.io/callbacks/
from keras.callbacks import History
# https://keras.io/layers/convolutional/
from keras.layers.convolutional import Conv1D
# https://keras.io/layers/core/
from keras.layers import Activation, Dense, Dropout
# https://keras.io/layers/embeddings/#embedding
from keras.layers import Embedding, Flatten
# https://keras.io/layers/pooling/
from keras.layers.convolutional import MaxPooling1D
# https://keras.io/getting-started/sequential-model-guide/
from keras.models import Sequential
# https://keras.io/utils/
from keras.utils import np_utils
Once we have those imports out of the way, the code to load our data looks like:
print("Reading in the preprocessed data...")
# pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_csv.html
df = pd.read_csv("new-tokenized-20-char.txt.gz", header=None, dtype=np.int8)
# Describe what we've read-in
print ("Raw dataframe...")
# pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.shape.html
count_row = df.shape[0]
print ("rows =",count_row)
count_col = df.shape[1]
print ("cols =",count_col)
# pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.info.html
df.info()
# Now break out the Y and the X's from the consolidated training file
print ("Y data...")
# pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.iloc.html
Y = df.iloc[:,0]
count_row_Y = Y.shape[0]
print ("rows =",count_row_Y)
print (Y.value_counts())
X = df.iloc[:,1:21]
print ("X data...")
X.info()
Running just the imports and the read-the-data-in statements we’ve just shown, we see:
$ python3 just-the-first-part.py
Using Theano backend.
Reading in the preprocessed data...
Raw dataframe...
rows = 3264272
cols = 21
RangeIndex: 3264272 entries, 0 to 3264271
Data columns (total 21 columns):
0 int8
1 int8
[etc]
20 int8
dtypes: int8(21)
memory usage: 65.4 MB
Y data...
rows = 3264272
0 3036657
1 227615
Name: 0, dtype: int64
X data...
RangeIndex: 3264272 entries, 0 to 3264271
Data columns (total 20 columns):
1 int8
2 int8
[etc]
20 int8
dtypes: int8(20)
memory usage: 62.3 MB
That all looks about the way we’d expect. Now it’s time to dig into the “red meat” of our neural network model.
Section 7. The Keras Sequential Model
You can read a nice overview of the Keras sequential model at https://keras.io/getting-started/sequential-model-guide/
The Keras sequential model is built up in layers. In a typical Keras sequential model there will be an input layer, one or more intermediate (“hidden”) layers, and an output layer.
If you review “How to choose the number of hidden layers and nodes in a feedforward neural network?”^26 you’ll learn that:
• The Input Layer:
“With respect to the number of neurons comprising this layer, this parameter is completely and uniquely determined once you know the shape of your training data. Specifically, the number of neurons comprising that layer is equal to the number of features (columns) in your data.”
• The Hidden Layer(s):
“In sum, for most problems, one could probably get decent performance (even without a second optimization step) by setting the hidden layer configuration using just two rules: (i) number of hidden layers equals one; and (ii) the number of neurons in that layer is the mean of the neurons in the input and output layers.”
Another response from that same thread commented:
“Problems that require two hidden layers are rarely encountered. However, neural networks with two hidden layers can represent functions with any kind of shape. There is currently no theoretical reason to use neural networks with any more than two hidden layers.”
When it comes to the number of neurons to use in each of those hidden layers,
“There are many rule-of-thumb methods for determining the correct number of neurons to use in the hidden layers, such as the following:
- The number of hidden neurons should be between the size of the input layer and the size of the output layer.
- The number of hidden neurons should be 2/3 the size of the input layer, plus the size of the output layer.
- The number of hidden neurons should be less than twice the size of the input layer.”
• The Output Layer:
“If the [Neural Network] is a classifier, then it also has a single node unless softmax is used in which case the output layer has one node per class label in your model.”
In our case, the sequential model we finally ended up with was as follows:
- We know that our first layer will be an embedding layer because that layer, if used, must be the first layer in your model.[^27] Recall that we needed an embedding layer because we had an unworkable number of dummy coded/indicator/”one hot” variables, 39 dummy variables for each letter in up-to-20-character-long domain names.
- Then we’ll have a Conv1D convolution layer. Why use a convolutional layer? Well, as was noted in Isak Bosman’s “A Convolutional Neural Network Tutorial in Keras and Tensorflow 2:”^28
“When identifying images or objects a great solution is to look for very similar pixel arrangements or patterns (features). But image recognition or object classifications are not the only uses for CNN’s. They have proven useful in many general classification problems. By using smaller regions or filters a Convolutional Neural Networks scale[s] far better than regular neural networks and makes it a great starting point for any classification problem.”
- Then we’ll add a MaxPooling1D layer. Again quoting from Bosman:
“A pooling layer is responsible for dimensionality reduction to ultimately prevent overfitting. By reducing the computations and parameters of the network it allows the network to scale better and at the same time provide regularization. Regularization allows the network to generalize better which ultimately improves the performance of the network over unseen data. The most common pooling layer types are Max Pooling and Average Pooling. In the practical CNN example later in the article, we will look at how the Max Pooling layer is used. Max pooling is by far the most common pooling layer as it produces better results.”
- Next comes a Flatten layer. The Flatten layer reformats multidimensional data received from a previous layer down to a single dimension.^29
- Then there will be a hidden dense layer^30 of size 40.
- Then we’ll add a 2nd hidden dense layer of size 20 (even though we shouldn’t need it, it seems to help).
- And finally, given that we’re interested in categorization/predicting class membership, we know that our last layer will be a 3rd dense layer of size 1.
Putting that all together, the model building statements look like:
print ("Starting to build a Sequential model...")
model = Sequential()
print ("Adding embedding...")
model.add(Embedding(40+1, 20, input_length=20))
print ("Adding convolution layer...")
model.add(Conv1D(filters=40, kernel_size=6, activation='relu'))
print ("Adding MaxPooling1D layer...")
model.add(MaxPooling1D(pool_size=3))
print ("Adding Flatten layer...")
model.add(Flatten())
print ("Adding 1st Dense layer...")
model.add(Dense(40, activation='relu'))
print ("Adding 2nd Dense layer...")
model.add(Dense(20, activation='relu'))
print ("Adding 3nd Dense (output) layer...")
model.add(Dense(1, kernel_initializer='uniform', activation='sigmoid'))
Section 8. Layer Parameters
You’ll notice in the above model that at least some layers require additional parameters. Where did we come up with those?
For example, what did we use for an activation function? And what IS an “activation function?” Wikipedia knows: “In artificial neural networks, the activation function of a node defines the output of that node given an input or set of inputs.”^31 Think of an activation function as being like an audio “sound mixer” or like a “truth table” in logic.^32
So which activation function do we want to use? Quoting “A Practical Guide to ReLU: Start using and understanding ReLU without BS or fancy equations,”^33
“ReLU is the most commonly used activation function in neural networks, especially in [convolutional neural networks]. If you are unsure what activation function to use in your network, ReLU is usually a good first choice.”
See also “Activation functions and it’s types-Which is better?”^34 which states:
“Almost all deep learning Models use ReLu nowadays. But its limitation is that it should only be used within Hidden layers of a Neural Network Model.”
So what are we going to do for our NON-hidden binary categorization output layer? We’ll try Sigmoid^35 for the output layer given that this is a binary categorization problem.
Now, how about initializers? First, what are they? Quoting “What are kernel initializers and what is their significance?”^36
“The neural network needs to start with some weights and then iteratively update them to better values. The term kernel_initializer is a fancy term for which statistical distribution or function to use for initialising the weights. In case of statistical distribution, the library will generate numbers from that statistical distribution and use as starting weights.”
We’ll use “uniform” (aka RandomUniform) for our initializer. There’s evidence in favor of more complex initializers,^37 but RandomUniform has worked well in our tests and is conceptually simpler than some alternative initializer distributions.
Section 9. Compilation, Training and Saving The Model
When our model is complete, we’ll “compile it” within Keras. in this case, that means using commands such as:
sgd = optimizers.SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='binary_crossentropy', optimizer=sgd, metrics=['accuracy'])
After the model is compiled, it then needs to be trained. This is the step that often can take some time.
Since we’re still unbalanced with respect to our classes (albeit not as badly as initially), we’ll use class weights to further upweight the “looks-random” class:
class_weight = {0: 1.,
1: 13.}
results = model.fit(X,Y,epochs=3,batch_size=32,class_weight=class_weight)
Once we’ve fit our model,^38 we’ll want to save it, so we don’t need to retrain the model every time we want to use it to make predictions:
model_json = model.to_json()
with open("model.json", "w") as json_file:
json_file.write(model_json)
model.save_weights("model.h5")
Compiling and training our model requires us to specify (or accept a default value for):
- An optimizer
- A loss function, and
- A metric.
When it comes to the optimizer, we chose Stochastic Gradient Descent (SGD) combined with “mini-batches”[^39] and with Nesterov^40 enabled. As noted in “Types of Optimization Algorithms used in Neural Networks and Ways to Optimize Gradient Descent,”^41
“An improvement to avoid all the problems and demerits of SGD and standard Gradient Descent would be to use Mini Batch Gradient Descent as it takes the best of both techniques and performs an update for every batch with n training examples in each batch. […] Mini-batch gradient descent is typically the algorithm of choice when training a neural network nowadays.”
When it comes to the loss function, the tutorial “How to Choose Loss Functions When Training Deep Learning Neural Networks”^42 states:
“Binary Cross-Entropy Loss
Cross-entropy is the default loss function to use for binary classification problems. It is intended for use with binary classification where the target values are in the set {0, 1}. Mathematically, it is the preferred loss function under the inference framework of maximum likelihood. It is the loss function to be evaluated first and only changed if you have a good reason. Cross-entropy will calculate a score that summarizes the average difference between the actual and predicted probability distributions for predicting class 1. The score is minimized and a perfect cross-entropy value is 0. Cross-entropy can be specified as the loss function in Keras by specifying ‘binary_crossentropy‘ when compiling the model.”
And finally, when considering metrics, we’ll use “accuracy” since this is a classification model. https://keras.io/metrics/ states that
“A metric function is similar to a loss function, except that the results from evaluating a metric are not used when training the model. You may use any of the loss functions as a metric function.”
Section 10. Running and Saving The Model
The full deep learning/neural network program can be found in Appendix III.
We’ll run that program by saying:
$ python3 run-model-embeddings.py > run-model-embeddings.out
Disregarding the “reading-in-the-data” output we’ve already considered, the output in run-model-embeddings.out lets us watch how our model run:
Starting to build a Sequential model...
Adding embedding...
Adding convolution layer...
Adding MaxPooling1D layer...
Adding Flatten layer...
Adding 1st Dense layer...
Adding 2nd Dense layer...
Adding 3nd Dense (output) layer...
Compiling...
Fit...
Epoch 1/3
32/3264272 [..............................] - ETA: 26:04:01 - loss: 1.7335 - acc: 0.5938
[...]
4288/3264272 [..............................] - ETA: 20:41 - loss: 1.3414 - acc: 0.1905
[...]
11360/3264272 [..............................] - ETA: 12:45 - loss: 0.7840 - acc: 0.6533
[...]
16416/3264272 [..............................] - ETA: 11:04 - loss: 0.5686 - acc: 0.7550
[...]
43776/3264272 [..............................] - ETA: 8:33 - loss: 0.2527 - acc: 0.9005
[...]
97536/3264272 [..............................] - ETA: 7:44 - loss: 0.1409 - acc: 0.9501
[...]
1055712/3264272 [========>.....................] - ETA: 5:12 - loss: 0.0399 - acc: 0.9900
[...]
3264272/3264272 [==============================] - 450s 138us/step - loss: 0.0259 - acc: 0.9939
Epoch 2/3
[...]
3264272/3264272 [==============================] - 334s 102us/step - loss: 0.0158 - acc: 0.9966
Epoch 3/3
[...]
3264272/3264272 [==============================] - 328s 101us/step - loss: 0.0140 - acc: 0.9970
We ran for 3 epochs because the model rapidly converged — when we tried running for a longer number of epochs, the loss and accuracy functions did not materially improve
Section 11. Applying the Estimated Model To Some New Data
All of the above aside, how well does the model find examples of random-looking domains in new data?
We’ll use another tranche of encoded SIE Channel 204 data to find out (domain names with more than 20 characters were dropped):
$ wc -l data-for-evaluation-up-to-20-only.dat
2,297,048 data-for-evaluation-up-to-20-only.dat [commas added for readability]
When compressed with
gzip -9
, that file is about 14MB in size. We’ll run that new data against the previously-fitted-model using the code shown in Appendix IV.
When run, the output of that code shows that 7,701 domains were identified by the neural network as being likely random-looking. That amounts to 1/3rd of 1% (7701/(7701+2289347))*100=0.335%) of all the observations in that file. We saved the probability of each record belonging to class 1, (e.g., of being “random-looking”) to
predictions.txt.
Those entries consisted of the observation number (starting with zero) and the associated probability of that particular observation being a random-looking domain name.
$ head predictions.txt
0 0.00022143000000000000
1 0.13626889999999999836
2 0.00000000001915007000
3 0.25894797000000002729
4 0.02492478999999999875
5 0.00000000000031461942
6 0.00000000000000000012
7 0.00000000000000000130
8 0.00134795000000000010
9 0.00000000000000000000
$ tail predictions.txt
2297038 0.00000000000406899560
2297039 0.00739000999999999981
2297040 0.08140785000000000382
2297041 0.11263989000000000640
2297042 0.99884002999999998984
2297043 0.00000000011643725000
2297044 0.03041506000000000071
2297045 0.00000000092432967000
2297046 0.00000010344766000000
2297047 0.00000000000000004514
We sorted those lines with the command:
$ sort -k2 -k1 -g < predictions.txt > predictions2.txt
$ head predictions2.txt
9 0.00000000000000000000
132 0.00000000000000000000
141 0.00000000000000000000
155 0.00000000000000000000
190 0.00000000000000000000
193 0.00000000000000000000
210 0.00000000000000000000
224 0.00000000000000000000
227 0.00000000000000000000
240 0.00000000000000000000
$ tail predictions2.txt
47029 0.99999154000000001208
1271572 0.99999179999999998625
1629556 0.99999199999999999200
826923 0.99999212999999997908
33180 0.99999249999999995087
1428758 0.99999249999999995087
17114 0.99999269999999995662
1429084 0.99999320000000002651
42830 0.99999439999999994999
2259341 0.99999607000000001467
Graphing the row-number-in-the-sorted-file vs the probability-of-membership-in-class=1, we got a graph with a very sharp knee:
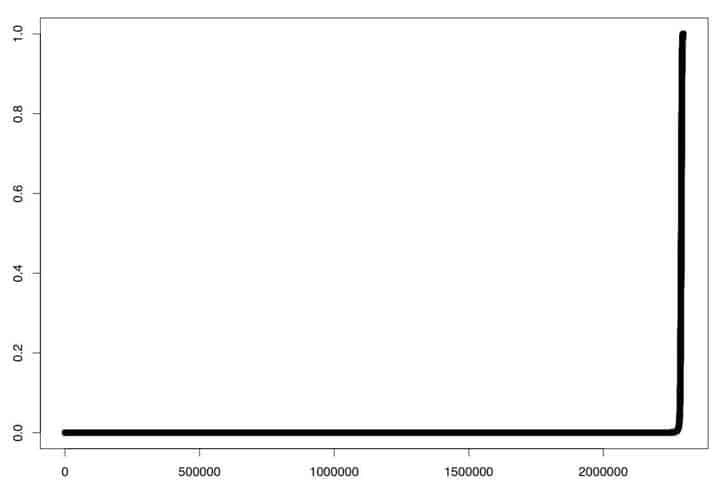
Figure 3. Probability of Membership in Class=1 vs. Dataset Row Number in Sorted File
This graph illustrates the fact that the model was “quite sure” that the vast majority of the observations were NOT random (e.g., there was very little degree of uncertainty for the wide flat region). For most observations in the test dataset, the model predicted virtually no chance of membership in class=1.
With a normal threshold of >=0.5, just ~1/3 of 1% of all observations were predicted as being being in class=1 (e.g., “random-looking”), see the “vertical” piece of the graph.
Even if we tag everything with a >= 0.05 chance-of-being-class=1 (a very, very, very permissive threshold) as actually being class=1, that still only brings us up to 0.58 of 1% of observations. See Table 3:
Table 3. Called Class Membership Probability Distribution
But what do the 7,701 observations that are at or above 0.5 probability for class=1 membership look like? Has the neural network/deep learning model actually worked? Do those observations actually appear “random looking?” We’ll need to dig into those observations to see.
We could just use
awk
to print the hits (e.g., imagine a script with 7701 lines that look like)
awk 'NR == 838543+1' sorted-and-uniqued-for-keras-test-20-or-less.txt
awk 'NR == 86223+1' sorted-and-uniqued-for-keras-test-20-or-less.txt
awk 'NR == 722473+1' sorted-and-uniqued-for-keras-test-20-or-less.txt
[etc]
Each of those statements would work to print one domain name from the test dataset,43 however that’s a crude approach and slow to execute. We’ll sort the list of hits in ascending order, and then use the little
python3
script shown in Appendix V instead.
The contents of extracted-records.txt as output by that program looks like:
000222y8.com
000365dd.com
001yixue.com
0022hhgj.com
006qd4pi.com
[...]
zzxydqwx.com
zzyc88888.com
zzyzx888.com
zzz01234.com
zzzzz666.net
Those sure seem like some pretty random-looking domains! After a superficial look, we’re cautiously optimistic. But what do we see if we then run those results through the
find-words.py
script from Part 1 of this blog?
Section 12. Dictionary “Pollution” in The Dictionary From Part 1; Dictionary Oversights/Omissions
Surprisingly, when we attempted to cross-validate the full set of “class=1” results found by the neural network/deep learning model with our
find-words.py
code from part I of this blog, we found some results that the neural network/deep learning model flagged as random looking (and which looked random to us), but which
find-words.py
reported as containing “words.”
Looking at one result flagged as “random” by the neural network (but which had many “words” when checked with
find-words.py
), we saw:
15 sdfghjkl com ['dfgh', 'dfghj', 'dfghjk', 'fgh', 'fghj', 'fghjk', 'fghjkl', 'ghj', 'ghjk', 'ghjkl', 'hjk', 'hjkl', 'sdfg', 'sdfgh', 'sdfghj']
Candidly, we’re not very impressed with the quality of some of the “words”
find-words.py
found. So how did those “words” get into the word list or “dictionary” that drives
find-words.py
? We believe our dictionary of words (as used in Part I of this blog series) may have been “polluted” by our decision to add some inadequately-screened “word lists” that were created for use in conjunction with password cracking.
In this particular case, if you look at the middle alphabetic row of a normal western keyboard, you’ll notice “sdfghjkl” is the sequence of letters making up the middle row. Thus, from a password cracking perspective, it makes sense to include “sdfghjkl” (and subruns thereof) since users are known to routinely employ runs of characters from their keyboard’s physical layout as their password. In fact, however, those “words” are NOT what most people would consider to be real English (or foreign language) words (as that term is normally used).
Another example of how we may have issues around word quality in our consolidated “dictionary:”
9 xclwxhjwudftlpnxm me ['dft', 'hjw', 'lpn', 'nxm', 'pnx', 'tlp', 'udf', 'wud', 'wxh']
That name sure looks like a random domain to us – and to our neural network – despite having nine “words” from our original “dictionary.”44 A final clearly-random-looking example with four low-quality “words:”
4 yxvxsdncysvxvcykv la ['cyk', 'ncy', 'sdn', 'svx']
At the same time we reached the conclusion that there are some “words” that clearly need to come out of our consolidated dictionary, we also noticed that there are still some all-too-common words that are unexpectedly missing from our dictionary, such as the “pseudo-word” “www”.
Clearly, further review and curation of our dictionary is warranted. Once that’s completed, the training data can then be recategorized, the models retrained, and the test dataset re-evaluated, etc. For that reason, we’re not going to show detailed comparisons of categorization accuracy, etc., in this article.
Section 13. Conclusion
You’ve now seen how neural networks can be used to successfully categorize domain names as “random-looking” or normal domains.
You’ve also seen how neural networks can highlight issues with other approaches to name categorization, such as issues with dictionary contents in our “look-for-English-or-foreign-language-words” approach.
We hope that you’ll be inspired to develop your own models (and word lists!) to identify random-looking domains, perhaps trying alternative neural network architectures such as recurrent (“LSTM”)45 models.
And if you need data for that testing, consider talking to Farsight Security sales about access to Channel 204 at the Security Information Exchange. With access to Channel 204, you could see how your own ideas for spotting algorithmic domain names measure up!
The Farsight Security Sales Team can be reached at [email protected] or give them a call at +1-650-489-7919.
Acknowledgements: I’d like to thank my Farsight colleague Kelvin Dealca for his comments on a draft version of this article. That said, any/all issues that may remain are solely the responsibility of the author.
APPENDIX I. CONVERT5.F
! compile with: $ gfortran -o convert5 convert5.f
!
! following text uses a tab for the initial spacing on each line
implicit none ! convert Y (1st column), space, then up to 20 char domains
character*20 domainname
character*39 validchars
character*1 char_to_match
integer class
integer location
integer maxwidth
integer maxcols
integer i,j ! domain name max width maxwidth = 20 ! valid characters: 26 letters + 10 number + 3 punctuation=39 chars validchars = 'abcdefghijklmnopqrstuvwxyz0123456789-_.'
maxcols = 39
open(5,file="combined-20-or-less.dat", status='old',
1 action='read')
100 read (5,"(I1, X, A20)",end=99999) class, domainname
write (*,"(I1,',')",advance="no") class
do j=1,maxwidth ! characters to translate ! what character are we looking for? char_to_match= trim(domainname(j:j)) ! find the index of that char in validchars location=index(validchars,char_to_match)
write(*,"(i2,',')",advance="no") location
enddo
write (*,"(X)")
goto 100
99999 continue
end
APPENDIX II. TRIM-TOO-LONG
#!/usr/bin/perluse strict;use warnings;my $threshold;my $length;my $line;
$threshold = $ARGV[0];if ( $#ARGV == -1) {die "must specify maximum OK length as first command line ar
gument\n"};if ( $threshold <=0 ) { die "maximum length must be > 0!\n" };while ( $line = <STDIN> ) {
chomp( $line );
$length=length( $line );
if ( $length <= $threshold ) { printf( "%s\n", $line ); }
APPENDIX III. RUN-MODEL-EMBEDDINGS.PY
#!/usr/bin/env python3
# http://www.numpy.org/import numpy as np# https://pandas.pydata.org/import pandas as pd# https://docs.python.org/3/library/sys.htmlimport sys# https://stackoverflow.com/questions/7370801/measure-time-elapsed-in-pythonfrom timeit import default_timer as timer# https://keras.io/losses/
# https://keras.io/optimizers/from keras import losses, optimizers# https://keras.io/callbacks/from keras.callbacks import History # https://keras.io/layers/convolutional/from keras.layers.convolutional import Conv1D# https://keras.io/layers/core/from keras.layers import Activation, Dense, Dropout# https://keras.io/layers/embeddings/#embeddingfrom keras.layers import Embedding, Flatten# https://keras.io/layers/pooling/from keras.layers.convolutional import MaxPooling1D# https://keras.io/getting-started/sequential-model-guide/from keras.models import Sequential# https://keras.io/utils/from keras.utils import np_utils
start = timer()
# we have unequal class counts, so we need to weight the 1's more heavily
# ref https://datascience.stackexchange.com/questions/13490/how-to-set-class-weights-for-imbalanced-classes-in-keras
class_weight = {0: 1.,
1: 13.}
# read the combined training data frame (the frame contains both
# a class variable we want to predict (Y) and a set of attributes (X's))
# ref https://www.shanelynn.ie/using-pandas-dataframe-creating-editing-viewing-data-in-python/
# data-for-training.dat looks like...
#
# 1 Y, 20 encoded X values (zero padded on the right for short names)
# the domain names were encoded a priori using convert5.f (outside of python)print("Reading in the tokenized data...",flush=True)
df = pd.read_csv("new-tokenized-20-char.txt.gz", header=None, dtype=np.int8)
end = timer()print ("After reading in training data, elapsed time in seconds =",(end-start))
# Describe what we've read-in
count_row = df.shape[0]
count_col = df.shape[1]print ("Raw dataframe...",flush=True)print ("rows =",count_row,flush=True)print ("cols =",count_col,flush=True)# https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.info.htmlprint ("-------------------------")
df.info()
# the first column (column 0) is Y
# (Y's coding: 0 ==> regular domain, 1 ==> random-looking domain)print ("Y dataframe")
Y = df.iloc[:,0]
count_row_Y = Y.shape[0]print ("rows =",count_row_Y)print ("-------------------------")print ("our Y values look like...")# https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.value_counts.htmlprint (Y.value_counts())# we've padded domains less than 20 chars long with zeros (blanks) on the
# right hand side of the row as part of our convert5.f processing, leaving
# us with uniform rows at this point
# https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.iloc.html
X = df.iloc[:,1:21]print ("-------------------------")print ("our X values look like...")
X.info()# see https://machinelearningmastery.com/tutorial-first-neural-network-python-keras/print ("Starting to build a Sequential model...")
model = Sequential()print ("Adding embedding...")# https://keras.io/layers/embeddings/model.add(Embedding(40+1, 20, input_length=20))print ("Adding convolution layer...")
model.add(Conv1D(filters=40, kernel_size=6, activation='relu'))print ("Adding MaxPooling1D layer...")
model.add(MaxPooling1D(pool_size=3))print ("Adding Flatten layer...")
model.add(Flatten())print ("Adding 1st Dense layer...")
model.add(Dense(40, activation='relu'))print ("Adding 2nd Dense layer...")
model.add(Dense(20, activation='relu'))print ("Adding 3nd Dense (output) layer...")
model.add(Dense(1, kernel_initializer='uniform', activation='sigmoid'))from matplotlib import pyplotfrom sklearn.manifold import TSNEdef plot_embeddings(embeddings, names):
model = TSNE(n_components=2, random_state=0)
vectors = model.fit_transform(embeddings)
x, y = vectors[:, 0], vectors[:, 1]
fig, ax = pyplot.subplots()
ax.scatter(x, y)
for i, tname in enumerate(names):
ax.annotate(tname, (x[i], y[i]))
pyplot.show()
embeddings = model.layers[0].get_weights()[0]
names = list(X.keys())# plot_embeddings(embeddings, names)print ("Compiling...")
sgd = optimizers.SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='binary_crossentropy', optimizer=sgd, metrics=['accuracy'])print ("Fit...")
history = model.fit(X,Y,epochs=3,batch_size=32,class_weight=class_weight)
end = timer()print ("After fitting the model, elapsed time in seconds =",(end-start))print ("Evaluate...")
scores = model.evaluate(X, Y, verbose=0)
print("%s: %.2f%%" % (model.metrics_names[1], scores[1]*100))print ("Summarizing...")print("model.summary()=",model.summary())print ("Saving the model")# https://machinelearningmastery.com/save-load-keras-deep-learning-models/
# serialize model to JSON
model_json = model.to_json()with open("model.json", "w") as json_file:
json_file.write(model_json)
# serialize weights to HDF5
model.save_weights("model.h5")print("Saved model to disk")
end = timer()print ("Post model save, elapsed time in seconds =",(end-start))
Appendix IV. run-model-embeddings-2.py
#!/usr/bin/env python3
# http://www.numpy.org/
import numpy as np
# https://pandas.pydata.org/
import pandas as pd
# https://docs.python.org/3/library/sys.html
import sys
# https://keras.io/utils/
from keras.utils import np_utils
from keras.models import model_from_json
# load already built and estimate model
json_file = open('model.json', 'r')
loaded_model_json = json_file.read()
json_file.close()
model = model_from_json(loaded_model_json)
model.load_weights('model.h5')
print("Loaded model from disk")
#######################
print("Reading in the eval data...",flush=True)
df2 = pd.read_csv("data-for-evaluation-up-to-20-only.dat.gz",
header=None, dtype=np.int8)
count_row = df2.shape[0]
print ("rows =",count_row,flush=True)
count_col = df2.shape[1]
print ("cols =",count_col,flush=True)
Xprime = df2.iloc[:,0:20]
print ("Predicting...")
# https://keras.io/layers/embeddings/
Yprime = model.predict_classes(Xprime)
Yprime_probability = model.predict_proba(Xprime)
count_row = Yprime.shape[0]
print ("rows =",count_row,flush=True)
count_col = Yprime.shape[1]
print ("cols =",count_col,flush=True)
value, count = np.unique(Yprime, return_counts=True)
print (value,count)
# get ALL the results, not just a taste
np.set_printoptions(threshold=sys.maxsize)
f = open("predictions.txt","w+")
for i in range(len(Yprime)):
value = float(str(Yprime_probability[i]).replace('[','').replace(']',''))
value = f'{value:.20f}'
print(i, value, file=f)
f.close()
Appendix V. print-hits.py
#!/usr/local/bin/python3
# note that hits.txt MUST be sorted in ascending order
myhits = open ('hits.txt', 'r')
domains = open ('sorted-and-uniqued-for-keras-test-20-or-less.txt', 'r')
matches = open ('extracted-records.txt', 'w+')
linenumber = 0
domain = domains.readline().rstrip('\n')
myhit = myhits.readline()
while ((domain != '') and (myhit != '')):
if (int(myhit) == linenumber):
print (domain, file=matches)
myhit = myhits.readline()
domain = domains.readline().rstrip('\n')
linenumber = linenumber + 1
myhits.close()
domains.close()
matches.close()
[^1]: I quote:
>"No matter what function we want to compute, we know that there is a neural network which can do the job. What's more, this universality theorem holds even if we restrict our networks to have just a single layer intermediate between the input and the output neurons - a so-called single hidden layer. So even very simple network architectures can be extremely powerful."
>See <http://neuralnetworksanddeeplearning.com/chap4.html>
[^2]: See https://meta.wikimedia.org/wiki/Cunningham%27s_Law
[^3]: See for example https://www.stata.com/support/faqs/statistics/stepwise-regression-problems/
[^4]: A particularly scathing review: “The BS-Industrial Complex of Phony A.I.; How hyping A.I. enriched investors, fooled the media, and confused the hell out of the rest of us,” https://web.archive.org/web/20190626012618/https://gen.medium.com/the-bs-industrial-complex-of-phony-a-i-44bf1c0c60f8:
>"For the last few years, startups have shamelessly re-branded rudimentary machine-learning algorithms as the dawn of the singularity, aided by investors and analysts who have a vested interest in building up the hype. Welcome to the artificial intelligence bullshit-industrial complex."
[^5]: Is blockchain living up to the hype?
[^6]: An NVIDIA DGX-2 (see https://www.nvidia.com/en-gb/data-center/dgx-2/ at a mere ~$400K per https://www.zdnet.com/article/nvidia-dgx-2-review-more-ai-bang-for-a-lot-more-bucks/ sure would be handy, but even a $99 128-core NVIDIA Jetson Nano board would likely lower neural network training times (see https://smile.amazon.com/NVIDIA-Jetson-Nano-Developer-Kit/dp/B07PZHBDKT
[^7]: https://keras.io/
[^8]: http://www.deeplearning.net/software/theano/
[^9]: https://www.python.org/
[^10]: https://www.numpy.org/
[^11]: https://pandas.pydata.org/
[^12]:https://opensource.com/article/18/5/top-8-open-source-ai-technologies-machine-learning
[^13]:https://groups.google.com/forum/#!topic/theano-users/7Poq8BZutbY
[^14]:https://www.anaconda.com/distribution
[^15]: Python Environment
[^16] https://pypi.org/project/pip/
[^18]: We’re reminded of “The Surprising Creativity of Digital Evolution: A Collection of Anecdotes from the Evolutionary Computation and Artificial Life Research Communities”, https://arxiv.org/abs/1803.03453v1
[^20]: https://gcc.gnu.org/fortran/
[^21]: https://www.gnu.org/software/gzip/
[^22]: https://en.wikipedia.org/wiki/Level_of_measurement
[^23]: https://en.wikipedia.org/wiki/Collation
[^24]: https://en.wikipedia.org/wiki/Nonparametric_statistics
[^25]: https://machinelearningmastery.com/how-to-one-hot-encode-sequence-data-in-python/
[^27]: https://keras.io/layers/embeddings/ explicitly says “This layer can only be used as the first layer in a model.”
[^28]: https://mc.ai/a-convolutional-neural-network-tutorial-in-keras-and-tensorflow-2/
[^29]: https://keras.io/layers/core/
[^30]: https://keras.io/layers/cor
[^31]: https://en.wikipedia.org/wiki/Activation_function
[^32]: https://en.wikipedia.org/wiki/Truth_table
[^33]: https://medium.com/tinymind/a-practical-guide-to-relu-b83ca804f1f7
[^34]: https://towardsdatascience.com/activation-functions-and-its-types-which-is-better-a9a5310cc8f
[^35]: https://medium.com/aidevnepal/for-sigmoid-funcion-f7a5da78fec2
[^37]: https://becominghuman.ai/priming-neural-networks-with-an-appropriate-initializer-7b163990ead
[^38]: https://machinelearningmastery.com/save-load-keras-deep-learning-models/
[^39]: Revisiting Small Batch Training for Deep Neural Networks
[^40]: https://wiseodd.github.io/techblog/2016/06/22/nn-optimization/
[^43]: The row number needs to be incremented by one because python is zero origin (it counts from zero), while awk counts from 1.
[^44]: I’m willing to stipulate that “lpn” is a valid abbreviation for “licensed practical nurse”, and “tlp” is a valid abbreviation for “trust level protocol”, but nonetheless.
[^45]: See https://en.wikipedia.org/wiki/Long_short-term_memory (an excellent example of using LSTM to detect DGA domains can be seen at https://www.endgame.com/blog/technical-blog/using-deep-learning-detect-dgas)
Joe St Sauver Ph.D. is a Distinguished Scientist with Farsight Security®, Inc.
Notes
Read more from DomainTools


