I want to start the New Year by making a couple of predictions for how things will go in 2017. I’m going to predict that The Atlanta Falcons will beat the Green Bay Packers, that the Pittsburgh Steelers will lose to the New England Patriots and that the Falcons and Patriots will end up in the Super Bowl game. Now I know some of you will cry foul, saying that some of these events have already happened. I’m willing to go with you on that point. I regard many security feeds and industry blocklists of domains that same way; someone has already identified that there is a known threat just like we already know who is going to be playing in the Super Bowl. We all know that predictions that rely on what has already been observed aren’t really predictions at all, however security feeds that rely on what has been already observed have some important caveats that we can learn from. For example if you followed the NFL closely and could identify that one team played particularly stronger vs another team, you might be able to infer that they had an advantage against the other team. In security investigations we can use that same types of observations to learn about threat actors and how we can stay ahead of them.
At DomainTools, we like to give our customers not just the ability to see the known bad and find all of the resources tied to a threat actor, but also the ability to be predictive in nature.
One of the tools we give our customers to help judge whether a domain is good or evil is what we call our Risk Score. The DomainTools Reputation Engine generates this score. In this post I would like to dive a little deeper into our risk score and how you can use it in your business. I’d like to use the super bowl analogy to show you a little more about how our risk score is predictive in nature.
A portion of the daily results from PhishEye showing a risk score for newly registered domains that are infringing on Google in some way.
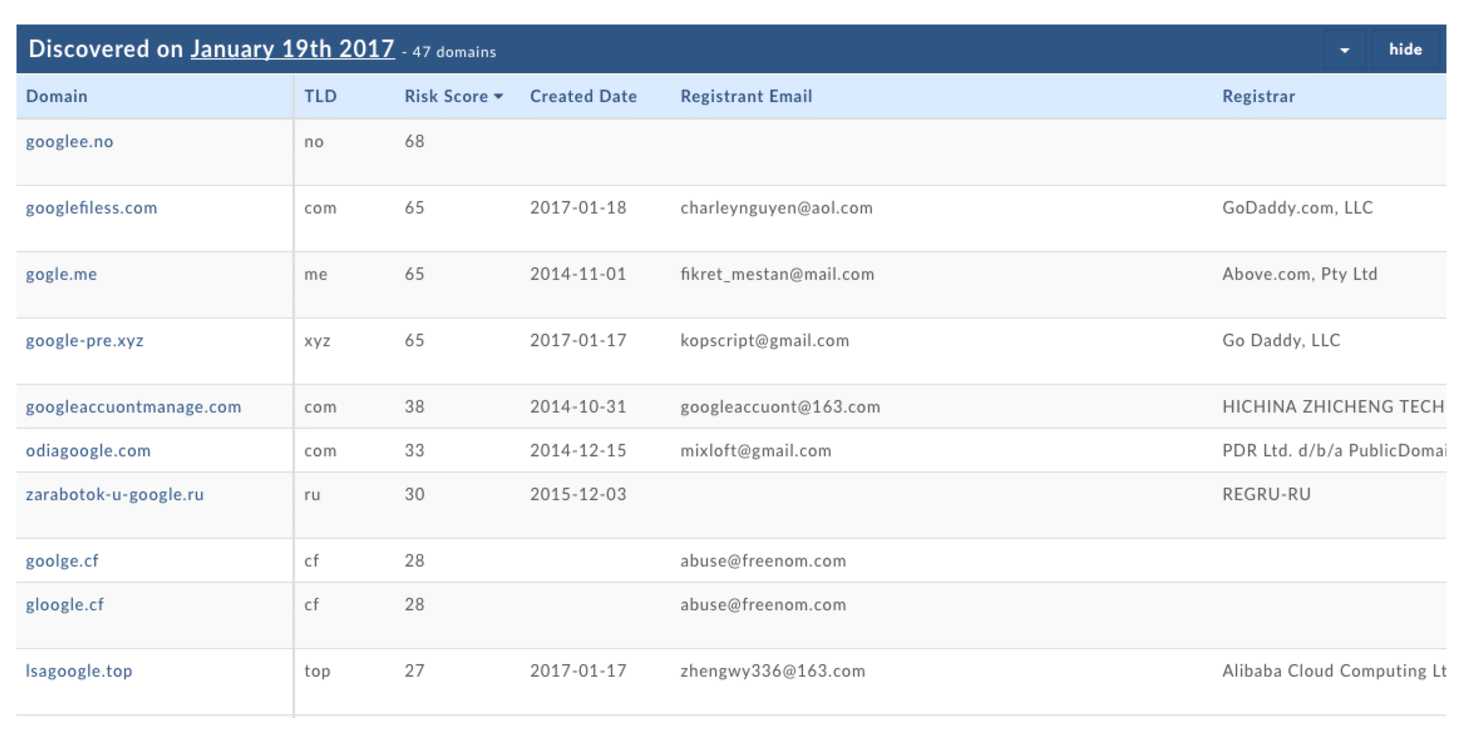
Of the approximately 315 million domains actively registered, there are a significant number of those domains that are historically “known bad” (they have been observed tied to malware, spam, credential theft, phishing etc.) There are several commercial providers of these feeds that companies can purchase and consume. This is a good thing, as it can protect you from known threats. At DomainTools, these blocklists of known malicious domains are one of the key data sources that we utilize in assigning a predictive risk score to a domain. All of the domains from those blocklist feeds are scored at a risk score of 100.
The rest of the domains registered that aren’t on an industry blocklist are scored from 0 to 99.99. I like to refer to this risk score as a predictor of the domain’s propensity to eventually end up on a blocklist. Without revealing all of the methodology we use to calculate the risk score, I’ll give some context. We’re looking at many details of each domain to determine how closely related it is to other known-blocklisted domains. For example, on the IP address that this domain is being hosted on, how many other domains are also on industry blocklists? With this registrant, how many domains do they have registered that are also blocklisted? As you can imagine, we are going through each domain and multiple attributes of the domain to make these calculations. A key advantage of this method is that the domain is scored immediately, so if these scores are used for policy enforcement, you can block a dangerous domain before it has been “weaponized.” This closes a window of vulnerability that exists with blocklists that are based on observing some kind of harm already being done by the domain.
Another example that I like to use to demonstrate the power of the risk score is to identify a registrant that has a brand new domain with a very high risk score and then to look at all of the domains registered by that person. We will almost always find that, of the domains registered by them, a very large percentage are already on an industry blocklist, so we can predict that anything newly registered by this same user is also very likely to end up on blocklists.
The next step after coming up with an algorithm like this is to do more research to find out where the inflection points are. In looking closely at the numbers, we discovered that domains that had a risk score of 70+ are very likely to end up on a blocklist, or to be associated with other known blocklisted domains, so they are really something you don’t want to see on your network. In the application that we built for Splunk, you can set a threshold for creating notifications based on domains seen on your network with a risk score of over a certain number; you can also search in Splunk for domains with a high risk score. Another consequence of our scoring algorithms is that domains that scored over 70 have a close to zero false positive rate.
Low risk scores, however, don’t necessarily mean that those domains are good, just that they don’t show a strong connection to the currently known blocklisted domains. For this reason, we like to use our risk score to predict bad domains vs. to list good domains.
As you hunt for evil inside of your network, it’s important to be able to arm yourself with the most up to date information possible. Risk scores are one of many powerful tools we provide to allow you to create your own threat intelligence.
Good luck hunting!