When we speak of the fundamental use cases for domain, DNS, and related data such as SSL certificates or screenshots, there is typically a base level of understanding of what we’re talking about and why it’s important. The conversations include things like:
- Developing more context around a domain or IP that may have been seen in an alert or event to understand whether it represents a threat
- Identifying connections between one observable (domain, IP, file, etc.) and others, to enumerate a larger set of assets that might represent a threat actor’s holdings, or an ongoing campaign
- Getting more details on what the actor might have in store for intended victims by studying various aspects of infrastructure (what “jobs” the different domains seem to exist to do)
But what we don’t always spend as much time on is how we can actually spot those potentially risky traffic flows, and how to knit together what we can see in the protected environment and what’s available from sources such as the DomainTools Iris Investigate or Farsight DNSDB databases. This blog seeks to delve into that space.
The Network Forensics Contact Patch
In the world of roadgoing vehicles, the term contact patch refers to the part of the tire that is in actual contact with the road—four, for a car, two for a motorcycle (unless it’s popping a wheelie, but that’s a different blog). All of the fancy engineering of the transportation aspects of that vehicle—the engine, transmission, suspension, brakes, and their ancillary systems—plays out in those relatively few square inches of contact between tire and pavement.
It’s like that with traffic flows in a protected environment, and the data that can help security folks make sense of those flows. When an Internet-related event occurs, packets flow from a client device to a server, and back from that server (yes, this is an oversimplification, but the concept works for our purposes here). The places where forensic “tire tracks” are left behind are the network forensics contact patch. Here are some examples:
- The DNS lookup made by the client for the domain for which the Internet traffic was intended
- The TCP or UDP traffic between the client and the Internet server
- The application-layer exchanges between the client and the server
- Actions applied by intermediary devices such as proxies or firewalls
If we are to get as much context as we can about the traffic flow in question, these are the places to look, because once we have extracted the key observables—domain name and IP address for our purposes today—we can then open up a can of OSINT (open source intelligence) on the flow to find out more about what’s really going on.
Looking for Domains in All the Right Places
Not every event recorded in the typical protected environment has a domain name associated with it. In fact, relatively few do. Fortunately, those few are present in every network, so you have the veins of gold; you just have to mine them.
Think about a basic Web transaction. Let’s say a user—we’ll call her Sarah—visits a web site. If she’s working in an office environment (or from home, but over a VPN that pushes all traffic through the office, which is common in many remote work environments), the web transaction will look different to us depending on where we’re viewing it. For example:
- If we’re looking at logs from that router, we’re unlikely to see the domain.
- If we’re looking at a packet dump from the internal interface of the edge router, we’ll see Sarah’s IP address, a source port, a destination port, and the IP address of the Web server. We can also extract the server name (with a domain) from the unencrypted part of the initial TLS handshake. However, packet dumps are not routinely collected at scale.
- If we have a deep packet inspection firewall or a web proxy, then we may see the headers from the HTTP/S exchange, depending on how logging is configured. This is one of the places in the “contact patch” where we can snag a domain name
- Looking a bit earlier in time—in order to facilitate Sarah’s connection to the Web site, her computer made a DNS lookup for the site’s domain. If the DNS resolver is logging its queries (meaning, just the cache-miss lookups to authoritative servers) then we’re going to get a two-fer from these logs: the domain and the IP to which it resolves
There are several reasons why it’s particularly valuable to get domain names in our logs and events—but those are matters we’ve discussed before (please do take a look if you’re curious!) For now, let’s assume we are resolved (sorry, not sorry!) that domains are valuable forensic artifacts.
If something about Sarah’s connection to that site raised an alarm—for example, if its IP address was on a reputation list for dangerous addresses—we would want to know more about the event. But if we only had that IP to go on, we would be left with some challenges:
- If the alert simply said, “Hey human, this protected IP address connected to this very nasty IP address on Port xx,” then we’d have to do a fair bit of digging to find out what the connection was really all about
- We could do a reverse lookup on the IP to see what domains are hosted on it—but that doesn’t tell us which of those domains Sarah was browsing to, unless we have other corroborating data
- And if we don’t know what domain it was, then we have a very incomplete picture of the event
So let’s get those domains from the logs!
The Dog That Caught the Car?
If we use all, or even most, of the log sources that could possibly give us domains in network transactions, we’ll get a lot of data. Much like the dog that actually caught the car he’d been chasing all those years, collecting all of these logs could give us more than we bargained for. That raises a few different matters we have to address, such as:
- Do we have the necessary infrastructure to capture, store, and analyze the significant level of log data we’re potentially going to collect?
- Is there any way that human analysts (especially ones pressed for time) can go through this mountain of data to pluck out specific network observables that might be forensically valuable?
If we were going to keep every single DNS record, we’d certainly be in for quite a data management problem. But what if we were to pre-filter the data to narrow it down? Are there methods we can use to curtail the records to a more manageable level while still retaining what might be important from an incident response or proactive defense perspective? The answer is yes. Yes, there are.
One of the most useful pre-filtering techniques would be to eliminate any DNS log data related to requests for popular domains. This will cut things down considerably, since the majority of your users (and even the non-user-initiated automated processes running in most environments) are sending traffic to relatively well-known resources. There are several resources available (after the demise of the famous Alexa web ranking service) that you might consider for getting this data:
- The Majestic Million — This is a pagerank-like list of 1-million-domains, updated regularly, under a Collective Commons/Attribution license (CC-BY)
- The Cisco/Umbrella top million — This is a User-system-DNS-requests list, released “free of charge” by Cisco
- Farsight Security’s passive DNS data — This is also a passive DNS list, but more by organization than by individual user
But even that might not be enough to narrow things down enough. If the amount of non-top-million log data is still too high, there are some other filtering criteria you could consider:
- For Web traffic, filter out any domains (URLs) that are categorized. Just leave the uncategorized domains for further scrutiny. This assumes that you trust your web filter’s categorization; sometimes new domains are difficult for filters to categorize
- Consider prioritizing certain subnets in your environment; for example, you could choose to apply this analysis only to traffic that originates from so-called “crown jewel” assets
If you choose to use one or more of these methods, you now have the ingredients for some paring-down of your domain list. What you’re aiming for is a much smaller list of domains that are not well-known on the web or to your filters. Some of those domains will likely be innocuous, such as your uncle Fred’s new vanity stamp collection site; but when it comes to malicious domains, a large proportion of them are young (recently created) and comparatively obscure (so they won’t be on that top-million list).
A good pre-filtering script might behave something like this:
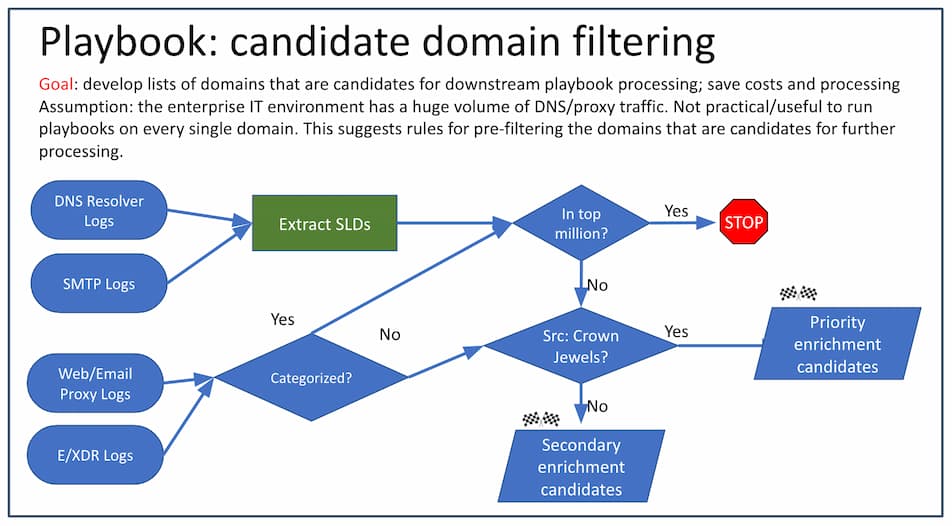
Getting Signal from the Noise
With this narrowed-down list of domains, we still need a programmatic way to identify the ones that might be most risky—especially if we’re planning on doing some hunting or some detection engineering based on what we learn about them. This is where enrichment of the domain names comes into play, often with tools such as SIEM and SOAR. In Part 2, we’ll look at how that enrichment can take place.