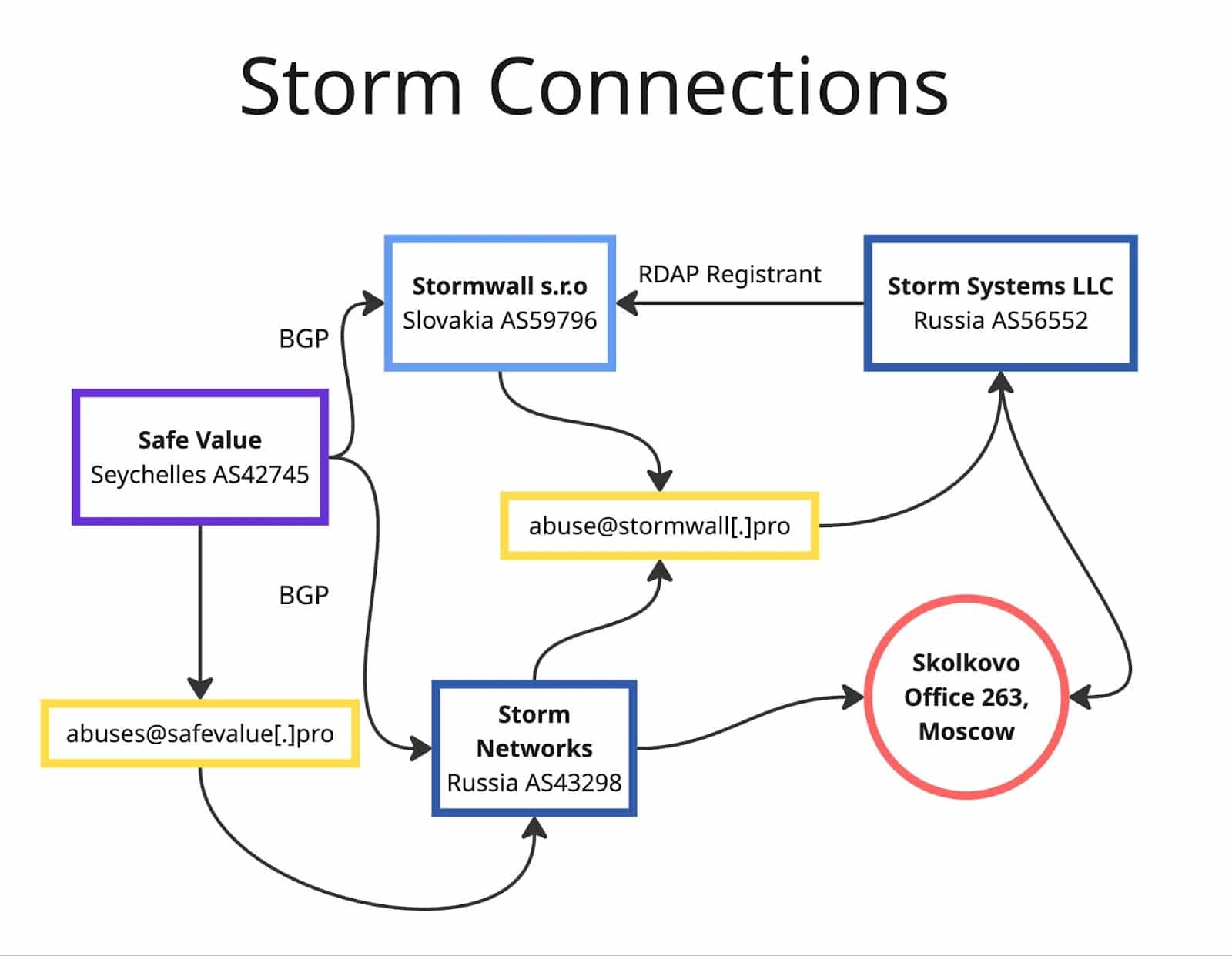
Introduction
In Part 1 of this series, we saw how hunting on adversary infrastructure can give a SOC team an important leg up on understanding what resources a hostile entity might be deploying against victims, in order to set up detection or blocking rules for defense or incident response. We saw that in order to develop the clearest possible picture of a malicious campaign, it is necessary to enrich the log data already available, in order to glean metadata that can help for the basis for connections that illuminate the larger structures that we glimpsed at first in the form of a single domain or IP address. And we saw how parts of that process can be automated, especially in the realm of enriching domain names with registration, hosting, content, and risk data.
The process of moving from wolf (a single domain) to pack (a set of infrastructure controlled by a given entity) involves pivoting on various data points. Pivoting is a familiar process to most SOC personnel; it can be done in various tools and with different areas of focus, from files to hosts to networks to organizations on both the victim and the adversary side of an event. As we saw in Part 1, DomainTools Iris provides “pivot count” information to guide investigators (or scripts) toward the pivots that are most likely to pay off.
The Definite Maybe
If we accept the assertion that there is a sweet spot in the pivot count, then for most investigations we can ignore as pivots any data point that has either zero or too many domains connected to it. An IP address with 400,000 domains sharing it is not a good pivot, nor is a generic email address such as “[email protected].” But there are many times when a pivot is a definite maybe: it might have relevant, related infrastructure tied to it, but confidence is low. These are cases where a human really has to make the call; ordinary SOC scripting and automation don’t have the right inputs and resources to make solid analytical assertions.
As an example, take the domain occert[.]email, which was embedded in a phish that spoofed a well-known bank. Its domain Risk Score of 79 shows that the DomainTools risk scoring algorithms found it to have attributes similar to malicious domains, though at least as of this writing, it had not landed on industry block lists. From a screenshot of Iris, we can see that one of the (only) two pivots that are guided is the IP address. (Guided pivots are called out in the UI by blue highlighting.)
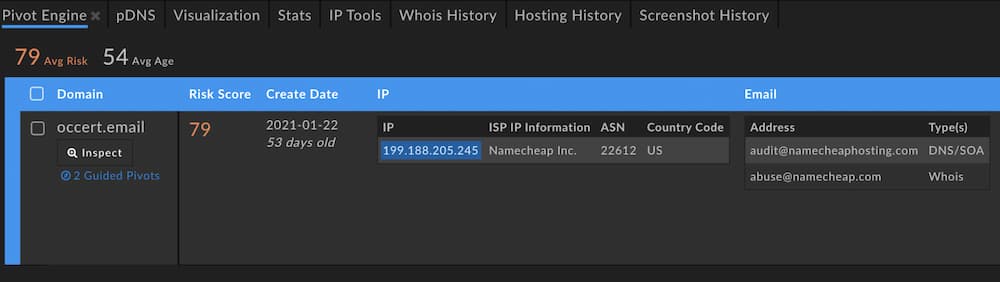
This IP has a pivot count within that sweet spot; in this case, our threshold is configured to 500, so any data point with more than zero but fewer than 500 domains will be highlighted. What would we see if we pivoted on that IP address?
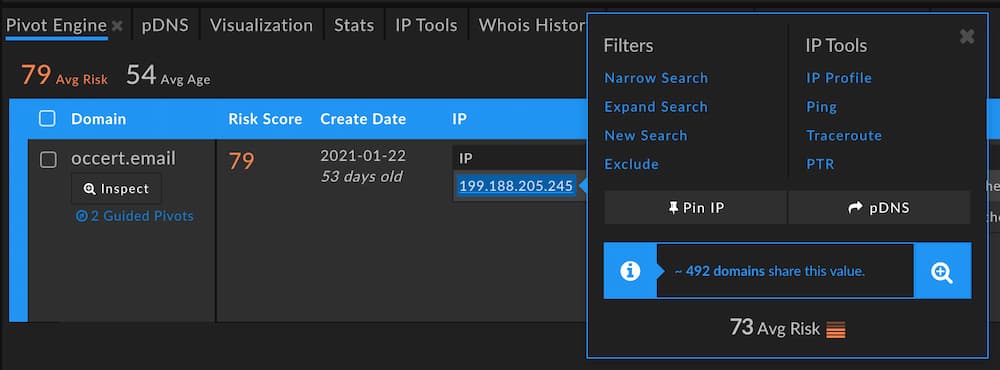
It barely made the cut as a guided pivot: 492 connected domains. With an average domain Risk Score of 73, though, there’s guaranteed to be some suspicious infrastructure behind that pivot. A preview of the domains on the IP gives us a better sense of its nature.
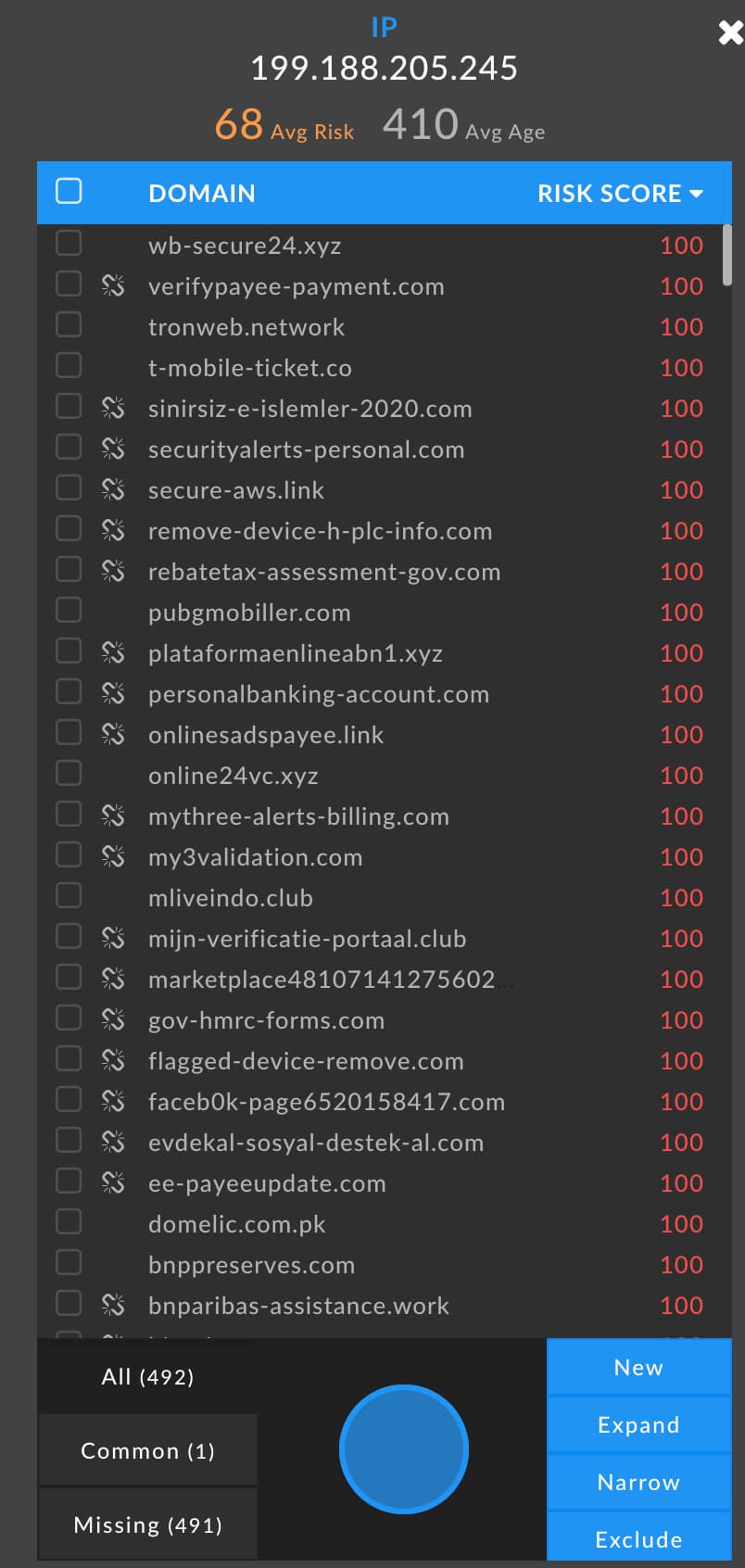
The domains connected to 199.188.205[.]245 are sorted by Risk Score, and all of those visible here have landed on block lists, hence the scores of 100. And a human can tell in an instant what would be much harder for automation to handle: there’s a lot of nasty here. Domain names like wb-secure24[.]xyz and t-mobile-ticket[.]co, with risk scores of 100 tied to them, make clear that this is a hostile chunk of the Internet. The risk scores add important context, too; a name such as t-mobile-ticket[.]co could plausibly belong to T-Mobile. If it had a Risk Score of zero, or an extremely low number, then it would not necessarily warrant much suspicion.
A human investigator might well decide to take this pivot and add the 492 domains to the search, because there’s a non-negligible chance that these domains are under the same control as the one we began with (occert[.]email). That set of domains would be a reasonable query for logs: did any host in the protected environment call out to any of those domains in the past? It would also be reasonable to create blocking rules against these domains, particularly if we filtered the list to just those domains at the highest end of the risk score spectrum. Odds are, such blocks would not impede legitimate business functions, and if occert[.]email already touched our environment, it’s not unreasonable to surmise that some of these others might be lying in wait. (It is worth noting that many of these domains are currently inactive as denoted by the broken-link symbol in the screenshot, so another filter could be to include only the domains that are still active.)
The Human-SOAR Handoff
In this example, a playbook could have done the following:
- Aggregate all log sources that have domain names available (more on this later)
- Normalize the logs and extract the domain names (at the SLD level, e.g. “example.com”)
- Write these to a file
- Look up all domains against the Alexa Top Million
- Discard domains in the Top Million
- Write remaining domains to a “candidate domains” file
The occert[.]email domain would have been in that candidate domains file, since it does not make the Alexa top million. The candidate domains could then be subject to another playbook:
- Look up Risk Score against the Iris Enrich API
- Generate lists of high- and low-risk domains
- From the high-risk domain list, query the Iris Investigate API for pivot counts
- Generate a list of high-risk domains that have at least one pivot within the threshold
If our threshold for “interesting” pivots in step 4 were set to 500, then the domain could be flagged for human follow-up. If the document generated by step 4 included the values that had interesting pivot counts, then it might look something like this (incidentally, “MXIP” is the IP address of the Mail Exchanger, or email server, associated with the domain):
| Domain | Risk | IP (count) | MXIP (count) |
|---|---|---|---|
| occert[.]email | 79 | 199.188.205[.]245 (492) | 199.188.205[.]245 (434) |
This document would be the human analyst’s hunting list, because they would know several important things about its contents. Every domain in the document:
- Has received traffic (or at minimum, DNS queries) from a protected host
- Has a high Risk Score from DomainTools
- Has other domains relatively closely coupled to it (based on the counts)
In large environments, such a list could be long, so some further pruning could be done as part of the playbooks; for example, in the second playbook, after step 1, a filtering step based on domain age could be added. Many analysts like to focus on newly-created domains. The domain occert[.]email was reported to a security trust group within a month or so of its creation; a playbook step to select-out domains older than, say, 90 days, would have included this domain at the time of its use in a phishing campaign, but might have trimmed down what the analyst had to pay attention to by discarding other domains that had been around longer.
With a few minutes in the Iris UI, the analyst could run the pivot on the IP and MXIP values for the occert[.]email domain, then do the following filtering:
- Ignore domains below a Risk Score of 70
- Ignore inactive domains
- Ignore domains over 90 days old
This yields a manageable indicator list of a few dozen, and the infrastructure has relevance because of its connection to a domain already observed on the network.
Grassroots Threat Intel
Creating threat intelligence in this way has an important advantage: it starts from a point of ipso facto relevance. Everything that occurs within your protected environment is relevant to you as a SOC staffer. To be sure, most of the traffic is benign in most environments; but when you start with something that is known or suspected to be malicious, and build your profile of the assets connected to it, you are starting from a good foundation. Most of the indicators in the major threat intel feeds never touch any given environment. It’s good to have access to those feeds, but it’s critical to spend precious resources on building situational awareness around what is known to be operating on your networks so you can fight what is actually being thrown at you.
More Help for the Definite Maybes
In this example, the connectedness of the domains related to occert[.]email was of a moderate confidence level. We certainly saw a lot of nasty-looking domains on the IP address, but there were not other indications that the domains were part of a specific campaign; they may have been the creations of various actors who happen to favor a particular hosting provider. How can we get more clarity on the relationships among domains to build a better understanding of a campaign? In Part 3, we’ll see a new tool developed by the DomainTools Research Team which aims to accomplish exactly that. Stay tuned!