

Introduction: It’s a Big CTI World Out There
The universe of cyber threat intelligence is vast; the number of available sources is already large and seems to grow daily. And a lot of individuals and companies are putting a lot of know-how and technology into the field, to help generate outputs that aim to make defenders’ lives a little easier. Even larger than the universe of threat intelligence, of course, is the data that gets turned into intelligence through various kinds of processing. All of this vastness can be a little intimidating, and even seasoned analysts and managers grapple with determining what sources and products will be of the most value.
The thing is, most of that threat intelligence, and even more so the raw data about potential threats, is not directly relevant to your organization. The world of threat intel is much bigger than the portion of it that touches your protected environment. In presentations, I depict it this way:
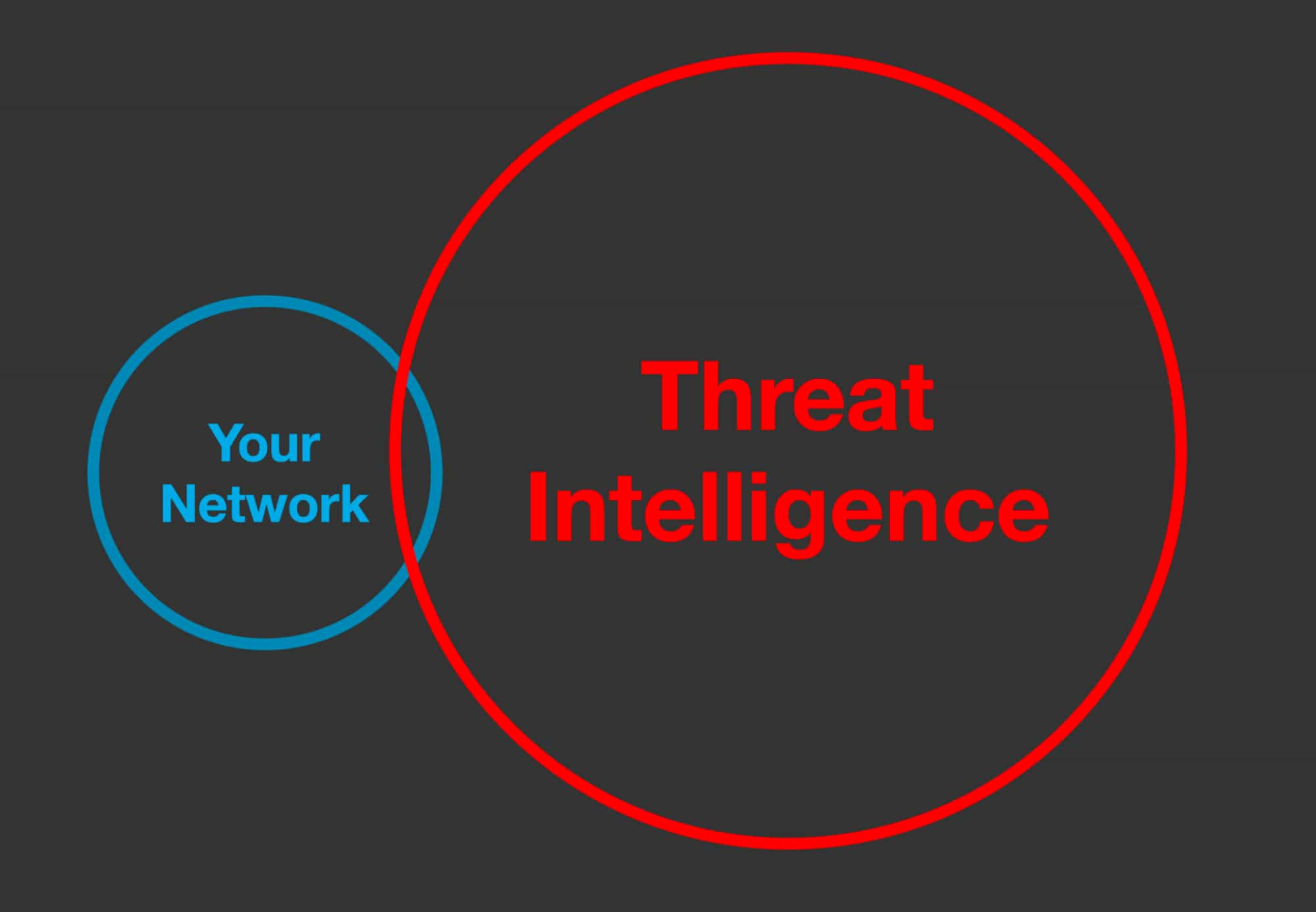
That little overlap in the Venn diagram represents where the data from external threat intel sources overlaps with what’s observed in your environment. Just how large the overlap is will vary, of course, so this is purely conceptual, but one data point comes from a very large financial services company whose CISO estimated the overlap at about 3%.
But there’s also a more pernicious problem: there are threats that are relevant to you, but which aren’t part of the threat intel that you’re consuming. In this next version of the diagram, the area bounded by the dotted line represents threats that you should care about, but that you won’t find in intel feeds.

And this is not dunking on threat intel feeds. It doesn’t mean they’re bad; it just means they’re not psychic. Most of these feeds depend on observations of badness in the wild. If it isn’t observed and reported (or discovered by researchers), it’s not in the feed. These undocumented threats are things like new or highly-targeted campaigns; they can cause damage while remaining invisible to almost everyone.
If the vast majority of threat intel data, through no fault of its own, is irrelevant to your organization at any given time, how do you capture what is relevant? This is where internally-generated threat intelligence is so valuable: it starts from a place of 100% relevance; that is, your own network traffic. This blog is about how to develop requirements for a specific species of threat intelligence, one based on DNS-related network observables.
What We Talk About When We Talk About Intelligence
It’s a matter of settled “law” that threat data does not equal threat intelligence. So in the formulation of your intelligence requirements, what you’re looking for is information that can give you insights into the nature and extent of a threat, and that can enable analysis that can in turn lead to more insights and better situational awareness. The aim of all of that, in turn, is to help you make good decisions about how best to defend your environment. If your requirements don’t make clear how the desired intelligence will inform specific kinds of actions, then the requirements aren’t done yet.
What We Talk About When We Talk About “DNS-Based”
For the specific intelligence we’re looking at here, the raw data we’ll be using is all related to DNS. Specifically, there is a lot you can learn when you do analysis on these types of data:
- Domains (including subdomains)
- IP Addresses
- Name Servers
- MX Records
There is a lot more to DNS than those four objects, of course; for a thorough discussion of the wealth of DNS and DNS-adjacent data, please see this excellent blog series by Kelsey LaBelle. But these four building blocks are available in the network traffic of pretty much any organization, and many of the other valuable DNS data points that turn your data into intelligence will come not directly from your network, but from resources that enrich the data observed on your network.
So, if you need domains, IP addresses, name servers, and MX records pertinent to network traffic in your protected, what will be your sources for those? Let’s consider some of the possibilities:
- Firewalls/IPS
- Web and SMTP proxies
- Routers
- Endpoints
- SMTP servers
- DNS resolvers
Not all of those sources can give you the record types you need. Routers, for example, will show IP addresses in their logs, but not any of the other data types. Some firewalls will provide domain names for some protocols, but for many others they, too, give mainly IP addresses. Web proxies generally will provide domain names, since they are processing traffic that specifically requests resources by strings (URLs) that contain domain names. SMTP proxies and servers likewise record domain names, since the domain is baked into the headers of the protocol. But if you had to pick just one of these sources, the DNS resolver would be at the top, because before anything in your protected environment talks to anything outside of it (including threat-actor-controlled assets), it asks the DNS server how to find it. (Yes, there are exceptions, where traffic goes directly to hard-coded IP addresses; but those are less common cases). So your local resolver is a rich source of the raw material you need in order to formulate good threat intelligence.
How Does DNS Data Become Intelligence?
The data you glean from any network observables is like gold ore: it’s necessary, but it doesn’t really shine until you’ve done some processing. So your DNS-based data needs to be enriched and analyzed, using tools and other data sets designed for that purpose. An example of enrichment would be to gather the current Whois record or Risk Score for a domain; another example would be so-called “reverse DNS” information for an IP address (to find out what other domains are hosted on it). Sometimes the original datapoint, plus its enriching data, provides enough context about the indicator that it can be considered intelligence; at other times, it will take some additional investigation to truly turn the corner to becoming useful intelligence. From the always-useful perspective of David Bianco’s Pyramid of Pain, this kind of enrichment is comparatively lightweight, yet can pay real dividends in adversary analysis, especially compared to resource-intensive activities like reversing suspicious binaries. (Not to say there’s anything wrong with the latter; it just tends to be time-consuming.)
To crystallize your intelligence requirements, ask yourself how you can:
- Assess the basic nature of something that’s been contacted by a protected host in your environment
- Determine whether that [domain|IP|mail server] is part of a larger threat
- Gain useful data for detecting and protecting against that larger threat (as well as retro-hunting in existing logs)
You’ll also want to figure out what your intelligence product(s) should look like. Your organization will have internal (and possibly external) requirements around reporting on threat activity. You’ll want to design your DNS-related threat intelligence gathering and processing to generate outputs that will easily flow into any reporting products you need to provide. This could be as simple as dumping high-confidence indicators into a spreadsheet, or producing a .pdf document with the indicators on it. It could also involve information sharing, such as with an ISAC; perhaps your shop uses STIX/TAXII for such sharing. If that’s the case, you’ll want scripting that outputs the critical indicators in a STIX document.
Signal: Noise Considerations
There’s certainly going to be a lot of noise in your DNS-based data sources, so part of your requirements might entail devising ways to decrease some of that noise. Let’s take the DNS resolver as the source. A DNS resolver on a large network is going to process a huge number of requests and replies. But as you create the pipeline of the log data to your threat intelligence systems (SIEM, TIP, etc), some pre-processing can help you narrow things down.
- Consider cross-checking domain names against the Alexa Top Sites, and discarding any domains found on that list
- If the volume is still too high to be manageable, consider filtering out requests that do not come from “crown jewels” network segments or individual hosts
- Consider filtering by TLD: while a lot of dangerous domains do exist in the .com and .net TLDs, you can still catch a lot of sketchy domains by looking at certain TLDs known to have a lot of evil on them, such as .xyz and .tk (in fact, you could simply make an exclude filter for .com and .net, and keep all the rest)
- A common use case for DNS analysis is to detect tunneling. There are regular expressions that can be used to detect unusual query strings; refer to this SANS paper for more details.
Your other sources can also benefit from some of the same pre-filtering, though most of them will be lower-volume than your DNS resolver. As an example, if you have a web proxy that categorizes URLs, consider enriching only those domains that come back as “uncategorized”.
Conclusion: You’re Sitting on a Gold Mine; Don’t Get the Shaft!
Your environment produces a wealth of DNS-based data that can be forensic gold, but until you have formulated and executed on processing and enrichment of the data, it’s just ore. Well-crafted intelligence requirements are like building the plan and designing the equipment for mining and extracting the gold and casting it into ingots or coins. It may seem daunting, but a lot of the familiar SOC tools have features to help you with this. You don’t have to (and probably shouldn’t) invent the end-to-end process anew. Once you have automated processes for developing true intelligence based on network observables in your environment, you can reduce the chances of being bitten by the various threats that are in play.


