

Depending on your interest in certain subjects, feel free to jump ahead:
How Does the Modern Whois Protocol Work?
Introduction
Building on our last installment focusing on the value of DNS data to analyze network infrastructure, in this blog we’ll continue to take a similar approach with the Whois dataset. Whois doesn’t receive the attention it deserves. In 2018 it seemed as if Whois fell from grace after GDPR (or the General Data Protection Regulation) entered stage left. I would argue this assumption is missing the boat. So today we’ll give Whois its moment in the sun as I cover the history of Whois, how it works, its unique value and limitations, complementary datasets, and action steps.

Abbott & Costello – Who’s On First?
What is Whois?
Whois, which isn’t an acronym, but a protocol, queries data managed by a number of entities known as registrars and registries. These organizations are governed by the Internet Corporation for Assigned Names and Numbers (ICANN). The databases managed by registries and registrars include names, addresses, emails, phone numbers, and administrative and technical contact information for internet resources (such as domains, IP address blocks, and autonomous systems). It may surprise you to learn that ICANN doesn’t have a super secret master database of all of the Whois records, since the zones are delegated. DomainTools, however, has the closest thing to the aforementioned database of Whois records in the world. We at DomainTools have been collecting this data for decades, so I’ve included an easter egg from an old DomainTools Whois record for your enjoyment.
The History of Whois
Remember our heroine, Elizabeth Feinler, from our previous blog? Turns out she did more than help put us on a path to the domain name system. In the early 70’s Feinler and her team also set up a server in Stanford’s Network Information Center (NIC) so they could find relevant information about people and entities associated with a given domain. Similar to DNS, there came a time to standardize what was a manual process. Ergo, the Whois protocol. This process came into existence in the early 80’s (and established in RFC 920) . There was one centralized server for all Whois queries as all domain registration was done one organization at a time. As the internet was segmented from the ARPANET, this process became more complex. The Defense Advanced Research Projects Agency (DARPA) was the sole organization responsible for domain registrations. Later, UUNET offered a domain registration service, more specifically the paperwork, which they forwarded on to DARPA. However, things changed when the National Science Foundation (NSF) handed over management of domain registration to commercial entities. Therefore, InterNIC was formed in the early 90’s under contract with the NSF. Up until the 2000s, Whois servers were nonrestrictive, which meant that you could conduct wild-card searches on a person’s last name and your query response would include all individuals with said name. Multiple groups took advantage of this capability, so searching became more restrictive.
In the final moments before widespread fear of Y2K (completely unrelated), management of top level domains (TLDs), which at the time were .com, .net, and .org, were handed over to ICANN. Existing Whois servers were decripated, and a month later in their place, a self-detecting Common Gateway Interface allowed for a web-based Whois lookup and an external TLD table to support multiple Whois servers based on the TLD of the request. Sound familiar? This is essentially the model for Whois used today.
With the proliferation of generic TLDs (gTLDs) and country code TLDs (ccTLDs) in the early 2000s, a more complex network of domain name registrars and registrar associations was born resulting in more commercial tools to conduct whois lookups. The evolution of Whois was far from complete. Next, the Internet Engineering Task Force (IETF) committee was formed in 2003 for the purpose of crafting a new standard for looking up information on domain names and network numbers and resulted in a proposed standard named the “Internet Registry Information Service (IRIS).” These new standards which were proposed by the working group Cross Registry Information Service Protocol (CRISP) are RFCs 3981, 3982, and 4992.
The Whois protocol isn’t set in stone. Not too long ago (2013), the IETF recognized that IRIS (not to be confused with DomainTools Iris) was too complex and wasn’t an adequate replacement for Whois. ARIN and RIPE NCC served Whois data in the meantime via RESTful web services. The working group then produced an additional five standard documents: RFCs 7480, 7481, 7482, 7483, 7484 and 7485.
How Does the Modern Whois Protocol Work?
As highlighted above, there have been many changes and evolutions of the Whois protocol. A client typically establishes communication using Transmission Control Protocol (TCP) to connect with servers via port 43. These servers host the databases noted in the “What is Whois” section on this blog. The client shoots a request and the response includes a test record identified from the database. You can directly query the database by way of your command line, or websites like research.domaintools.com.
Depending on certain contractual obligations for registries, a query will return a thick or thin Whois record. I’ve included the nuances of these two different record types below.
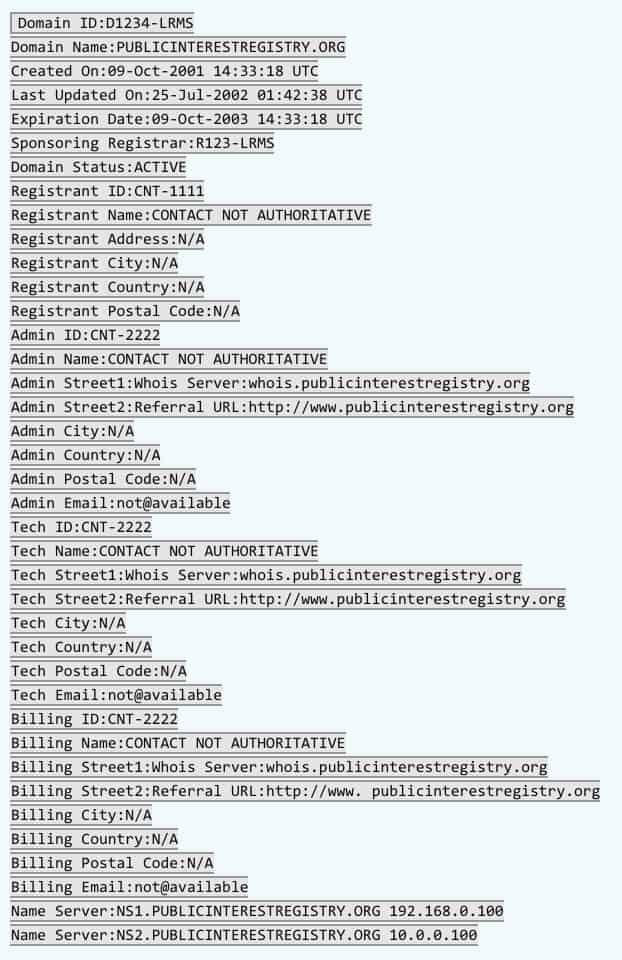
Lean/Thin Whois Records
Lean or thin records provide a more limited result set from the registry. They tend to include the registrar, status of the domain, and creation/expiration dates. See an example of a thin record below.
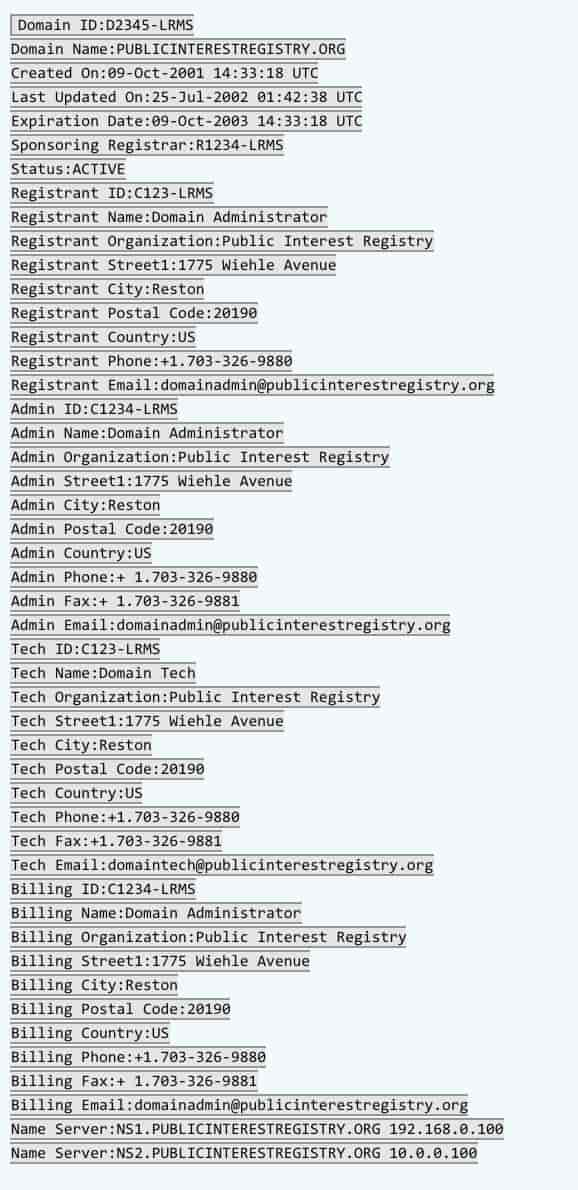
Thick Whois Records
As you might expect, thick records contain a fuller set of data; administrative and technical contact details in addition to what is included in the thin records. Here’s a sample thick record.
Valuable Artifacts From Whois
Domain Name
Alright, I’ll admit it. I’m cheating a little by filing the domain name under Whois data, but I hope you’ll bear with me. Domain names might range greatly in character length (the longest reported domain is llanfairpwllgwyngyllgogerychwyrndrobwllllantysiliogogogoch[.]co[.]uk, and the shortest, g[.]cn), but regardless of characters, domains are fairly easy and inexpensive to come by. They are also useful when it comes to profiling an adversary, and therefore more suitable for some methods of defending against potential attacks. Domain names can help you understand the scale of an operation, targeted industries (or lack of), specific techniques/operations used by a threat actor (i.e. command and control (c2), bulk domain registration (BDRA), domain generation algorithms (DGAs), phishing, and more), threat actor intent, and assess risk. Here are some patterns I hope you’ll find useful when peering at domain names.

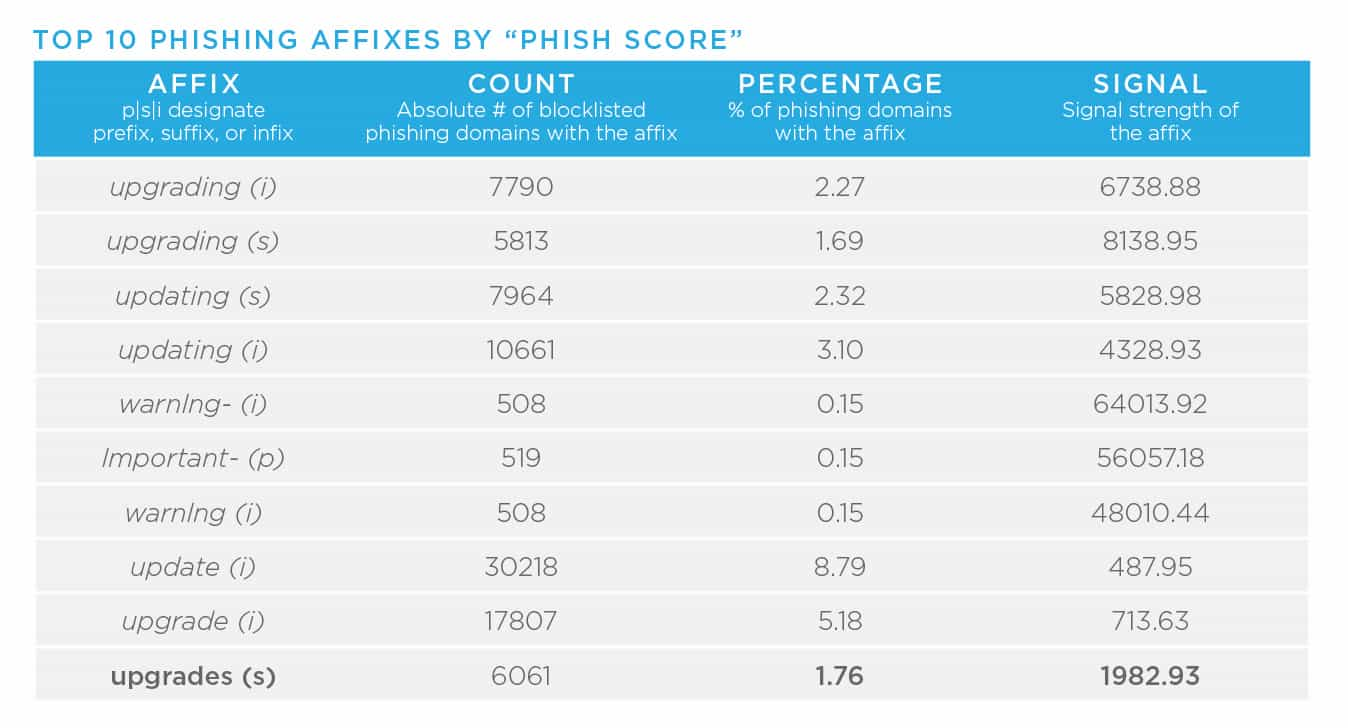
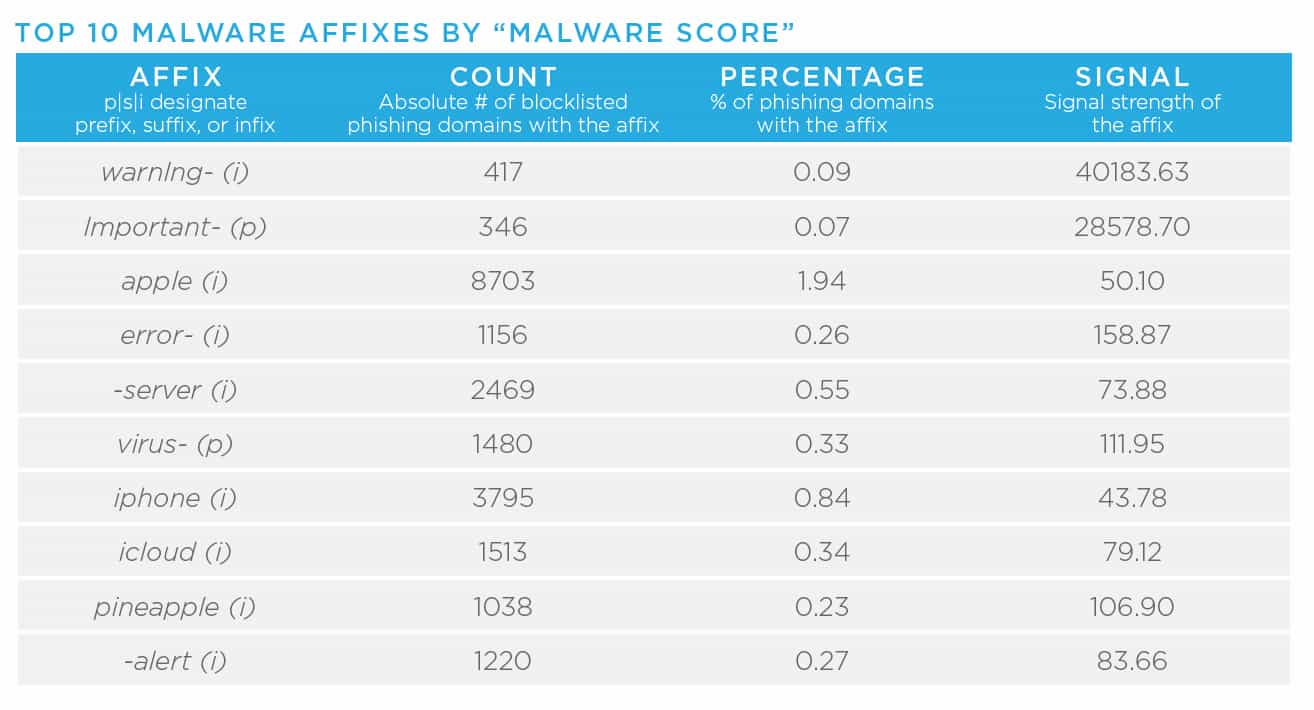
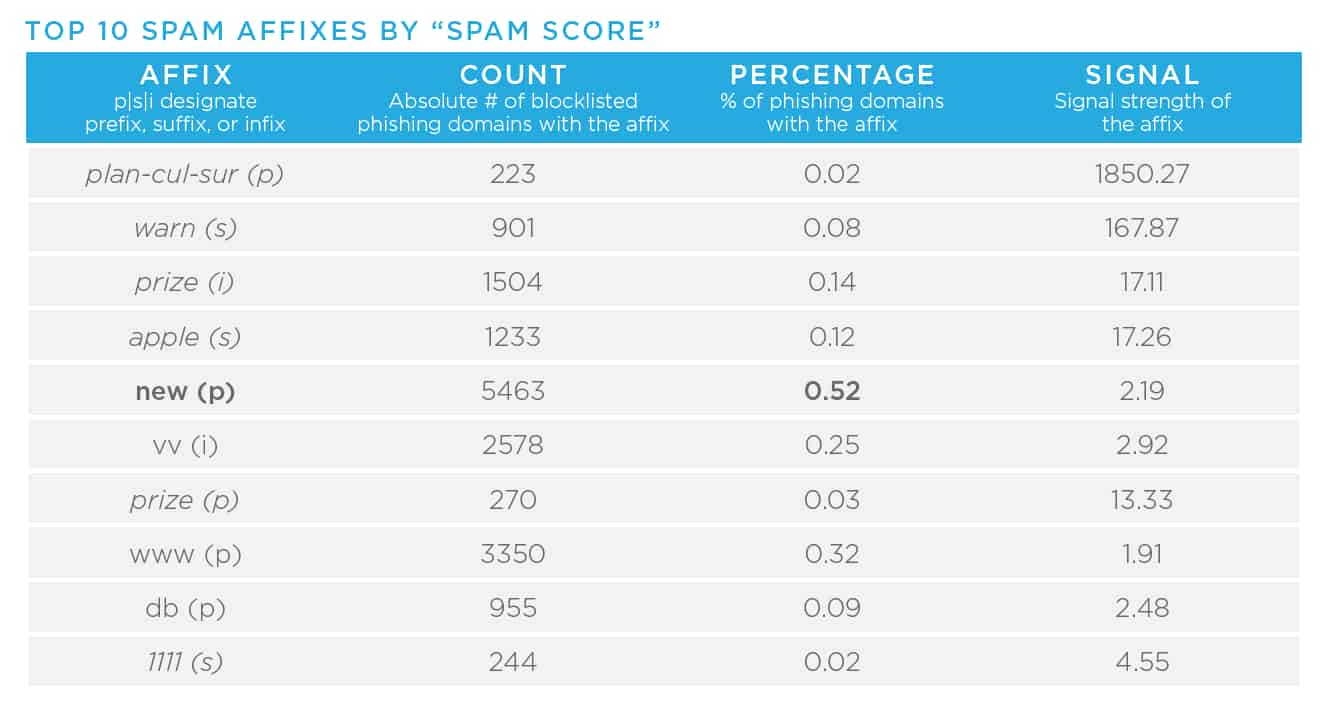
- Domain affixes, for example the term “logon” in the following domain, “logonmicrosoft[.]com,” allow malicious registrants to abuse widely recognized and trusted brand names. Other concerning affixes include “login,” “support,” “upgrade,” or “www.” As I mentioned in the previous blog in this series, the increase in the number of TLDs in conjunction with these affixes, gives malicious actors a vast number of potential names, which makes it very difficult for large organizations to prevent brand abuse. In other words, there is lots of opportunity for threat actors. In year’s past, our Research team has released reports detailing higher concentrations of badness on this topic. In these reports, data scientists have pulled apart affixes associated with phishing, malware, and spam. Here is the most recent data (2018), so it is likely these have evolved, but they do act as helpful starting points.
- Domain generation algorithms (DGAs) are a technique used to minimize blocklisting or take down of C2 infrastructure by threat actors. C2 infrastructure relies on fixed domains or IP addresses, so rather than cycling through or spinning up new infrastructure, nefarious actors will have malware switch to a new domain at regular intervals. In order to be successful, cybercriminals will try to make these routines as unpredictable as possible, and then purchase inexpensive domains, lock in operational security, and operate at high velocity. Our Research team conducted some research on dictionary based DGA spikes in our recent DomainTools Report. DGAs can take the form of gibberish strings with high entropy; they can also connect random words rather than letters (which can make them less obvious to humans reviewing logs or alerts). Outside of using machine learning to detect DGAs, taking a look at the entropy of a domain, whether or not the domain is allow-listed, and similar recently registered domain names are helpful approaches.
- Cultural trends are key as cybercriminals are efficient when it comes to opportunistic campaigns. Spikes in domains registered with similar names aren’t inherently risky, however they are worth keeping an eye on. Below is data from our Domain Blooms DomainTools Report. Here is an example of using cultural trends in a rather unpleasant way, and of course, an example with the global pandemic.
- Typosquatting is an incredibly common tactic applied by threat actors. This umbrella term includes a number of sub techniques:
- Adding or omitting alphanumeric characters (e.g. domainntools[.]com or domantools[.]com)
- Character flips (aka bitflips) (e.g. domaintoolq[.]com)
- Homophones or common misspellings
- Character substitutions, in particular substituting ASCII and/or unicode lookalike characters (e.g.. domaintoolz[.]com)
- Hyphen additions and/or removals
- Duplicate character reductions (e.g. domaintols[.com]
- Suffixes, similar to our earlier discussion on affixes (e.g. domaintoolscom.[biz])
- Homoglyphs, or domains using international characters (e.g. domainτools[.]com)
- Miskeyed replacements or additions (e.g. domaintrools[.]com)
- Substrings that return results that have a term as a substring of the domain (e.g. Secureaccountdomaintoolswebsite[.]com)
Registrant Data
In 2018 depending on who you were speaking to, GDPR was either a privacy advocate’s dream, or a four letter word for security professionals. This EU regulation law on data protection and privacy had a major impact on the availability of Whois information. In response, ICANN created a policy that redacted a number of personally identifiable information fields (PII) including registrant name, address (street, city, postal code), phone number, and emails. As many of you are aware, before GDPR there was domain privacy, a paid option for those registering domains to take advantage of proxy services in place of their private information. So frankly GDPR wasn’t a completely new barrier for security folks. I mention GDPR, however, to underscore that some Whois data is more limited than it has been historically.
Registration and Administrative Emails
- Unique emails in the clear, meaning they aren’t redacted by GDPR or registered under privacy, are useful when it comes to forging connections between domains as well as to profile threat actors. If you are able to track them down, be sure to unearth any other domains associated with the email. I’d recommend looking to see if you can find any start of authority (SOA) or secure socket layer (SSL) records that match your query.
- Email domains aren’t all created equal. Free email providers, not so surprisingly, have traditionally been associated with a higher concentration of badness. Here is a chart mapping out email domains to watch for. This data is harder to come by, so please excuse the dust it has collected and remember that these tactics do evolve over time.

Contact Information
- Registrant address information can shed a lot of light on the legitimacy of a registrant or registrant organization. Here are a things I recommend you look for:
- Elements of the address can be used to connect domains, this is most useful when there is a small number of domains that share common address traits, and a potential indication that the domains are related/connected.
- Googling the address to see if it actually exists. If it does, is it a place of business? Or perhaps a PO box or even a FedEx location near an airport. Sometimes you’ll find it is a sanctioned organization, which doesn’t mean something nefarious isn’t going on. I often look to see if the business has reviews and social media channels. Here’s an example where a shared hosting server was compromised rather than a single domain.
- Observing every component of an address to identify mismatches can be a signal that something is amiss. For example, does the postal code match the city listed? Is the street name associated with the city, etc.
- Registrant phone numbers play a similar role.
- Is the phone number the correct number of digits? Does it match the schema of the country associated with domain name or registration details?
- Additionally, some registrars require two factor authentication, so sometimes the phone number appears in the Whois data. Even if the threat actor uses a burner phone to register the domain, it is likely they will use the same phone number to register multiple domains, which could be a useful pivot to identify connected infrastructure.
- Registrant organizations with a small cluster of associated domains is a potential indication of connected infrastructure. Similar to a registration address or phone number, googling the organization to see if there are signals it is legitimate can be useful.
Registrar
- Registrar names are also great gut checks. Similar to bulletproof hosting, some registrars are more trusted than others. Unreliable registrars typically operate in countries that don’t have to respond to legal actions by the US or EU. China, Malaysia, and Russia are good examples. Like many of these signals, it isn’t enough to declare a domain or set of domains bad, but it is a good indication that it is worth your time to continue digging.
- Domain status codes are set by a domain’s registry. Client codes are used by the registrars, and server status codes are set up by registries. There is a full list of client and server codes on ICANN’s site. This likely tells you if a domain is active, transferring properly, if there are legal disputes, etc.
Dates
- Create dates are the tried and true indication of domain age. Defenders traditionally find younger domains to have a higher likelihood of maliciousness. A common rule of thumb is typically don’t trust domains younger than 30 days—especially if the web page is built to collect login or credit card information. Anecdotally, I’ll say that it is possible that domain age as a signal of nefariousness is shifting as cybercriminals and threat actors hold onto domains for a longer period of time before weaponizing or operationalizing infrastructure to improve their campaigns’ efficacy.
- Expiration dates are useful as well. These can be used to maintain your organization’s domain portfolio and ensure you don’t let a domain drop to be proactively picked up by an opportunistic threat actor for BEC or phishing attacks. A recently expired domain might also be a signal that a threat actor picked up a dropped domain to use for nefarious purposes.
Historical Whois
With the reality of both GDPR and domain privacy, historical Whois can be valuable, but will diminish as we move farther from when GDPR was put into effect. Having said that, oftentimes you can see some sloppy operational security when threat actors initially register a domain, and then flip it to privacy later. If the domain hasn’t moved around, you’ll also have the historical information to refer to information before it was redacted. This is a great technique to find emails and other PII in the clear. Also, even after GDPR, Registrant Organization is a field in Whois that can sometimes help you link clusters of activity.
IP Whois
IP Whois is a different beast than domain Whois. The Internet Assigned Numbers Authority (IANA) delegates resources to regional Internet registries (RIR), which in turn manage the allocation and registration of blocks of IPs and delegate them to Internet Service Providers (ISPs). I covered IP addresses in the previous blog post in this series, and I’ll also talk more about them in our upcoming blog on passive DNS (PDNS), but regardless, IP Whois still has a role to play.
- IP delegation/registration information shows the organization to whom this IP is delegated by a RIR. The organization identity in the IP Whois record gives a very general idea of the geographic region for the administrative aspect of the delegation, but this is not the same as IP geolocation services out there. You can figure out what region the IP is in by the globe by which RIR answers. Sometimes this can be enough to tell you if the IP may not align with a domain’s purported purpose.
- The traceroute command via your terminal or command line. can get you a layer closer to the location of the IP than the IP delegation data from the Whois record. Be aware, though, that this often will give only generalized location information, inferred from the host names of the intermediate hops closest to the target IP.
- Many analysts need more precise IP geolocation and there are a variety of services that provide this (it often takes a variety of datasets to determine location due to the complexity and layers of sub delegations).
| Region | Regional Internet Registry (RIR) |
|---|---|
| Africa | AFRINIC |
| Antarctica, Canada, parts of the Caribbean, US | ARIN |
| East Asia, Oceania, South Asia, Southeast Asia | APNIC |
| Caribbean and Latin America | LACNIC |
| Europe, Central Asia, Russia, West Asia | RIPE NCC |
Leveraging Whois Data in Your Environment
What Pairs Well with Domain Whois Data?
- DNS
- Passive DNS
- X.509 Security certificate information (e.g. SSL)
- Web page source and content
- Sender Policy Framework (SPF) and Domain-based Message Authentication, Reporting and Conformance (DMARC) rules
- Server type / Operating System (OS) and status (from server banners)
Follow Up Actions
As discussed in the previous installment of this series, there is added value in enriching an indicator with Whois data. An increasingly popular next step is to automate this process by using security orchestration automation and response (SOAR) platforms to build playbooks to help speed up your investigations without needing to add more resources to your team. Here are links to Tim’s blog series on SOAR:
- Streamlining Adversary Infrastructure Hunting With SOAR
- How To Build a Human Analyst’s Hunting List With SOAR Playbooks
- Exposing Possible Campaigns with DomainCAT
Tim also classifies the datasets highlighted in this series as characterizers (tell you something about an infrastructure element), connectors (help you find related assets), and identifiers (identification of malicious actors). These categories help you align your analysis goals with a particular piece of data.
Conclusion
Whois, like DNS data, is a wellspring of information that can allow you to quickly gather information to understand the intent, the relative risk, and relationships between pieces of infrastructure. Join me for the final blog in this series on passive DNS (pDNS).
Whois Cheat Sheet
| Record Type | Observation | Potential Indication |
|---|---|---|
| Domain Name | Typosquatting or non-typo spoofing (e.g. affixes/prefixes). | Suspicious infrastructure. |
| Domain Name | High entropy strings or a combination of random words. | Potential use of DGA technique. |
| Domain Name | Newly-registered, culturally-relevant themed domain names with close proximity to blocklisted infrastructure. | Suspicious infrastructure. |
| Registrant Email | Unique emails associated with other malicious domains, SOA records, or SSL records. | Suspicious infrastructure. |
| Registrant Email | Unique free email domains with a higher concentration of badness in combination with close proximity to known bad infrastructure. | Suspicious infrastructure. |
| Registrant Address | Elements of a unique address shared between a small number of domain names (especially if the domain names share a collective theme). | Shared domain ownership. |
| Registrant Address | Inconsistent or inaccurate address information that isn’t associated with a legitimate entity. | Suspicious infrastructure. |
| Registrant Phone Number | Inconsistent or inaccurate phone information that isn’t associated with a legitimate entity, or country/area code that doesn’t match the provided address. | Suspicious infrastructure. |
| Registrar Name | Registrars operating out of countries who aren’t likely to respond to legal actions by the US and EU. | Suspicious infrastructure. |
| Registrar Name | Registrars accepting cryptocurrency as payment can provide a safe haven for cyber-criminals. | Suspicious infrastructure. |
| Create Date | Domain age is less than 30 days. | Suspicious infrastructure. |
Download the full cheat sheet (includes DNS, Whois, Passive DNS)
Additional Resources
A Comprehensive Measurement Study of Domain Generating Malware
Domain Blooms: Identifying Domain Name Themes Targeted By Threat Actors


